10月21日~10月22日のビッグモデル日報集

【10月21日~10月22日のビッグモデル日報集】ChatGPTとDALL・E3の業界「ブラックトーク」発覚、220億個のトランジスタ、IBM機械学習専用プロセッサNorthPole、エネルギー効率25倍向上、マスク氏初xAIの研究結果を公開! 創設メンバーのYang GeとYaoクラスの卒業生による共著
ChatGPTとDALL・E3の間の業界「ブラックトーク」が発覚
リンク: https://news.miracleplus.com/share_link/11082
先月末、OpenAI は最新の画像ジェネレーター DALL・E 3 をリリースしました。爆発的な生成効果に加えて、最大のハイライトは ChatGPT との統合です。 DALL·E 3 は ChatGPT 上に構築されており、ChatGPT を使用してプロンプトを作成、拡張、最適化します。 こうすることで、ユーザーはプロンプトにあまり時間を費やす必要がなくなります。 ユーザーが DALL·E 3 アプリケーションの機能のテストを続けると、誰かが DALL·E 3 と ChatGPT の間で共有される内部プロンプトを明らかにする非常に興味深いバグに気づき始めました。 奇妙なことに、その指示には強調のためにすべて大文字で書かれたコマンドが含まれており、AI 間の人間のようなコミュニケーション能力の可能性を示していました。

GPT-4 を使用すると、ロボットはペンを回したり、クルミを皿に盛り付けたりする方法を学習しました。
リンク: https://news.miracleplus.com/share_link/11083
学習という点では、GPT-4 は素晴らしい生徒です。 大量の人間データを消化した結果、さまざまな知識を習得しており、チャット中に数学者のテレンス・タオにインスピレーションを与えることもできます。 同時に、本の知識を教えるだけでなく、ロボットにペンの回し方を教える優れた教師にもなりました。 Eureka と呼ばれるこのロボットは、Nvidia、ペンシルバニア大学カリフォルニア工科大学、テキサス大学オースティン校の研究の成果です。 この研究は、大規模言語モデルと強化学習に関する研究を組み合わせたものです。GPT-4 は報酬関数の改良に使用され、強化学習はロボット コントローラーのトレーニングに使用されます。 GPT-4 でコードを作成できる Eureka は、優れた報酬関数設計機能を備えており、独自に生成された報酬は、タスクの 83% において人間の専門家の報酬よりも優れています。 この能力により、ロボットは、ペンを回す、引き出しやキャビネットを開ける、ボールを投げたりキャッチしたり、ドリブルしたり、ハサミを操作したりするなど、以前は簡単に完了できなかった多くのタスクを完了できるようになります。 ただし、当面はすべて仮想環境で行われます。
GPT-4よりもコメント機能が強化されており、大型モデルAuto-Jはオープンソース13B評価に提出されています
リンク: https://news.miracleplus.com/share_link/11084
生成人工知能技術の急速な発展に伴い、大規模なモデルを人間の価値観(意図)と確実に一致させることが業界の重要な課題となっています。 モデルの調整は重要ですが、現在の評価方法には制限があることが多く、開発者は混乱することがよくあります。大規模なモデルはどの程度調整されているのでしょうか? これは、アライメント技術のさらなる開発を制限するだけでなく、技術の信頼性についての一般の懸念も引き起こします。 この目的を達成するために、上海交通大学の生成人工知能研究室は迅速に対応し、より透明性が高く正確なモデル値の整合性評価を業界と一般の人々に提供することを目的とした新しい値整合性評価ツール Auto-J を立ち上げました。
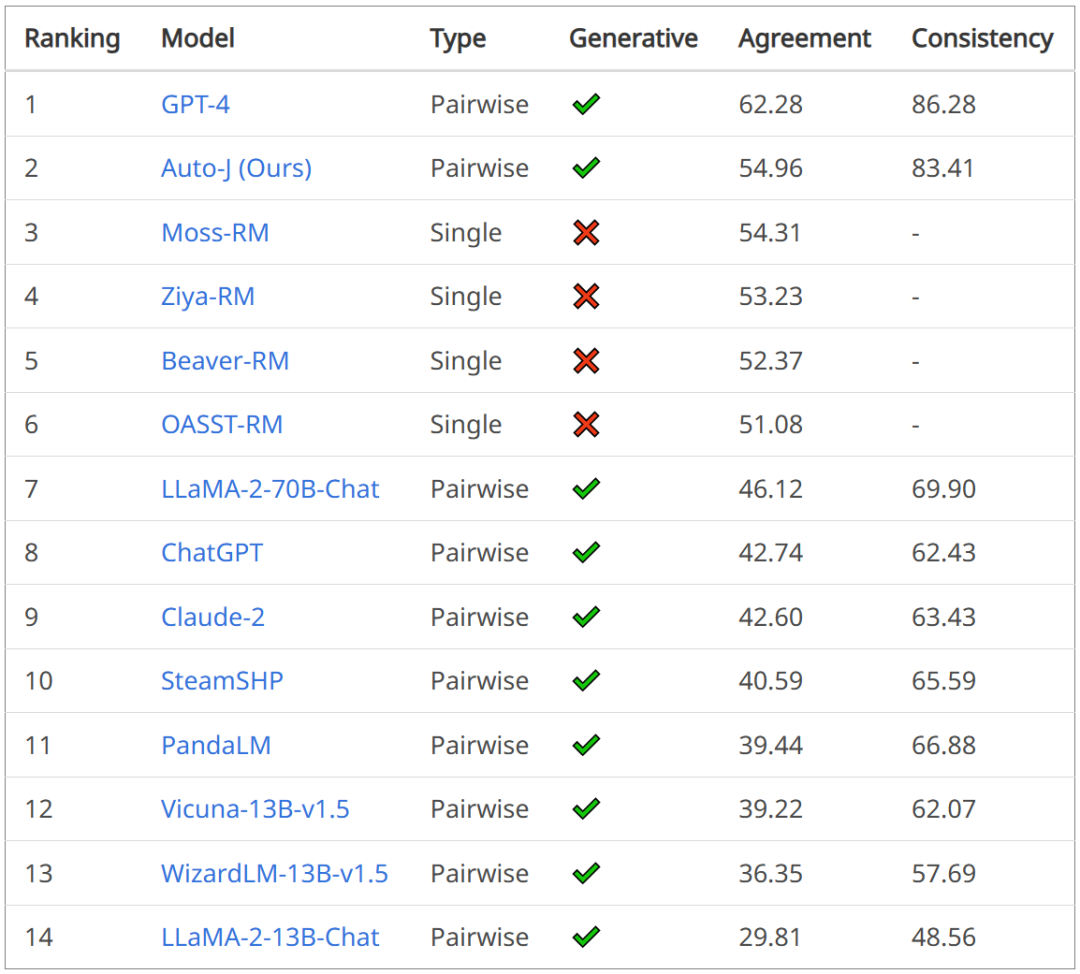
パラメータがほぼ半分であるため、パフォーマンスは Google Minerva に近くなります。もう 1 つの大規模な数学モデルはオープンソースです。
リンク: https://news.miracleplus.com/share_link/11085
プリンストン大学、EleutherAI などの研究者は、数学的問題を解決するためにドメイン固有の言語モデルをトレーニングしました。 彼らは次のように考えています: 第一に、数学的問題を解決するには、大量の専門的な事前知識とのパターン マッチングが必要であるため、ドメイン適応性のトレーニングには理想的な環境です。第二に、数学的推論自体が AI の中核的なタスクであり、最後に、実行する能力です。強力な数学的推論 言語モデルは、報酬モデリング、推論強化学習、アルゴリズム推論など、多くの研究トピックの上流にあります。 そこで彼らは、Proof-Pile-2 の継続的な事前トレーニングを通じて言語モデルを数学に適応させる方法を提案しています。 Proof-Pile-2 は、数学関連のテキストとコードを組み合わせたものです。 このアプローチを Code Llama に適用すると、数学的機能が大幅に向上した 7B および 34B の基本言語モデルである LLEMMA が作成されます。
大規模なモデルの再現と共同作業の難しさを解決するために、この 95 年代以降の学生チームは国内の AI オープンソース コミュニティを設立しました
リンク: https://news.miracleplus.com/share_link/11086
大型モデルの時代において、コミュニケーションやコラボレーションの敷居を下げる便利なプラットフォームをいかに構築するかが大きな課題となっています。 Git ベースのコード管理やバージョン管理など、私たちが慣れ親しんでいる従来のソフトウェア開発コラボレーション手法は、決定論的なプロセスよりも実験に依存する AI 研究開発などのシナリオにはもはや適用できない可能性があります。使用量や展開のしきい値が高いと、さまざまな分野の専門家間のコミュニケーションやコラボレーションが妨げられることがよくあります。 現在の AI 分野では、非技術的な背景を持つ専門家がモデルの開発、評価、デモンストレーションのプロセスに簡単に参加できるように、より直観的で使いやすいバージョン管理およびコラボレーション プラットフォームを含む、新しいコラボレーション モデルとツールが必要です。 言い換えれば、科学研究者と実務家の両者は、AI分野のさらなる発展を促進するために、知識と技術の共有に基づいてより効率的かつ綿密な協力を実現したいと考えています。 こうした背景から、新たなAIオープンソースコミュニティプラットフォーム「SwanHub」が誕生した。
220億個のトランジスタ、IBM機械学習プロセッサNorthPole、エネルギー効率が25倍向上
リンク: https://news.miracleplus.com/share_link/11087
AI システムが急速に発展するにつれて、必要なエネルギーも増加しています。 新しいシステムのトレーニングには大規模なデータ セットとプロセッサ時間が必要なため、非常にエネルギーを消費します。 場合によっては、よく訓練されたシステムを実行することで、スマートフォンがその仕事を簡単に実行できることがあります。 ただし、実行回数が多すぎると消費電力も増加します。 幸いなことに、後者のエネルギー消費を削減する方法はたくさんあります。 IBM とインテルは、実際のニューロンの動作を模倣するように設計されたプロセッサーを実験してきました。 IBM は、RAM への繰り返しアクセスを避けるために、相変化メモリ内でニューラル ネットワーク計算を実行するテストも行いました。 さて、IBM は別のアプローチをとりました。 同社の新しい NorthPole プロセッサは、上記のアプローチからのアイデアのいくつかを統合し、非常に合理化された計算実行方法と組み合わせて、推論ベースのニューラル ネットワークを効率的に実行できるエネルギー効率の高いチップを作成します。 このチップは、画像分類や音声転写などの分野で GPU よりも 35 倍効率的です。

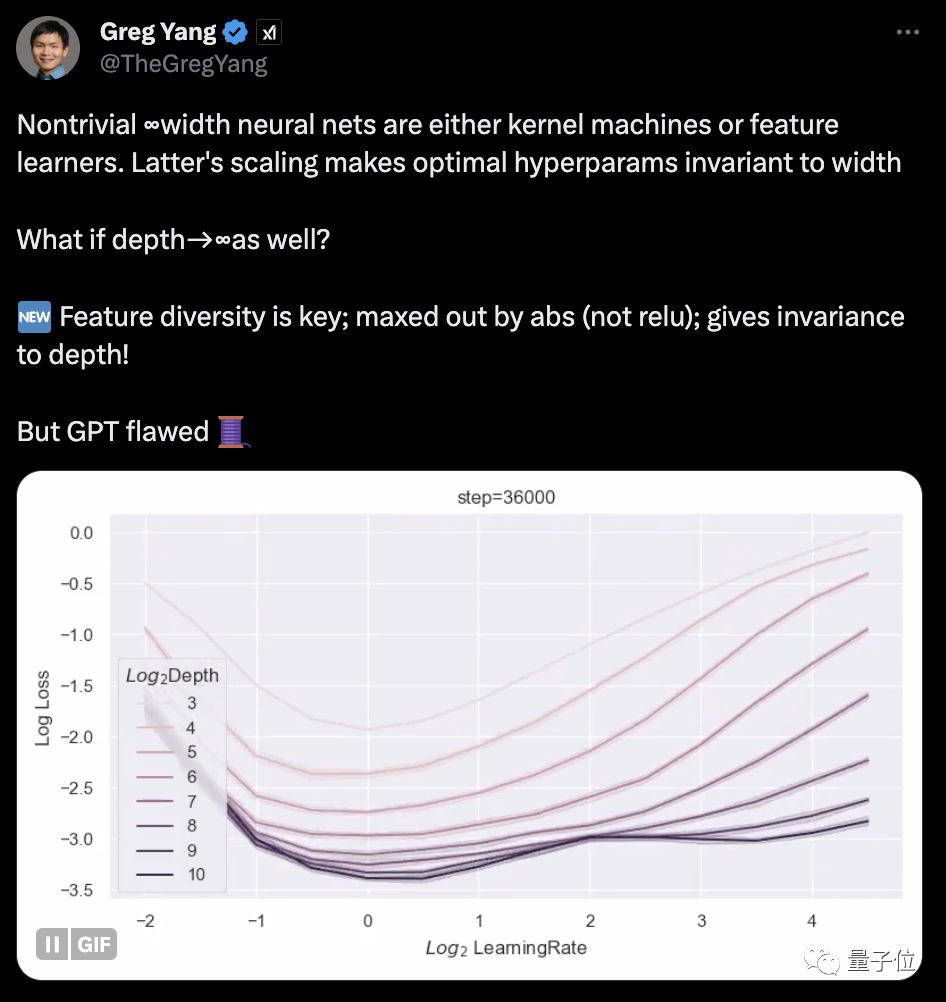
マスク氏初のxAI研究結果が発表! 創設メンバーのYang GeとYaoクラスの卒業生による共著
リンク: https://news.miracleplus.com/share_link/11088
マスク氏の xAI、初の公開研究結果が登場! 共著者の 1 人は、xAI の創設メンバーであり、Shing-Tung Yau の弟子である Greg Yang です。 Yang Ge 氏は以前、xAI における研究の方向性は「AI のための数学」および「数学のための AI」であると公に述べています。 重要なポイントの 1 つは、彼の以前の研究を継続することです。テンソル プログラムは、ニューラル ネットワーク アーキテクチャを記述するための統一プログラミング言語であり、関連する結果は GPT-4 に適用されています。 この新しい論文はこのシリーズに属し、「無限に深いネットワークを訓練する方法」に焦点を当てています。
LLaMA2 コンテキストの長さは 100 万トークンに急増し、調整が必要なハイパーパラメータは 1 つだけ | 復旦大学の Qiu Xipeng チームが作成
リンク: https://news.miracleplus.com/share_link/11089
ほんの少し調整するだけで、大規模モデルのサポート コンテキスト サイズを 16,000 トークンから 100 万トークンに拡張できます。 ! まだ LLaMA 2 を使用していますが、パラメーターは 70 億しかありません。 ご存知のとおり、最も人気のある Claude 2 と GPT-4 でさえ、コンテキストの長さは 100,000 と 32,000 しかサポートしていません。この範囲を超えると、大規模なモデルは無意味なことを話し始め、物事を記憶できなくなります。 今回、復丹大学と上海人工知能研究所による新たな研究では、一連の大規模モデルのコンテキスト ウィンドウの長さを増やす方法を発見しただけでなく、ルールも発見しました。
1 行のコードで大規模モデルのパフォーマンスが 10% 向上、開発者: フリーランチ
リンク: https://news.miracleplus.com/share_link/11090
大規模モデルの微調整には「フリー ランチ」があり、たった 1 行のコードでパフォーマンスを少なくとも 10% 向上させることができます。 パラメータが 7B の Llama 2 では、パフォーマンスがさらに 2 倍になり、Mistral も 4 分の 1 向上しました。 この方法は教師あり微調整フェーズで使用されますが、RLHF モデルもこの方法から恩恵を受けることができます。 メリーランド大学、ニューヨーク大学などの研究者は、NEFT(une)と呼ばれる微調整方法を提案しました。 これは、教師あり微調整 (SFT) モデルのパフォーマンスを向上させるために使用できる新しい正則化手法です。 このメソッドは、HuggingFace によって TRL ライブラリに組み込まれており、インポートにコードを 1 行追加することで呼び出すことができます。 NEFTは運用が簡単なだけでなく、大幅なコスト増もなく、「フリーランチ」のようなものだと著者は語る。
文字を入力するよりも大きなモデルの写真を効率的に見てみましょう。 NeurIPS 2023 の新しい研究では、精度が 7.8% 向上するマルチモーダル クエリ手法が提案されています
リンク: https://news.miracleplus.com/share_link/11091
大きなモデルの「画像を読み取る」能力は非常に強力ですが、なぜ彼らは依然として間違ったものを見つけてしまうのでしょうか? たとえば、コウモリと見た目が似ていないコウモリを混同したり、一部のデータセットで珍しい魚を認識できなかったり…これは、大規模なモデルに「何かを見つける」ように依頼する場合、入力がテキストであることが多いためです。 「コウモリ」(コウモリ?コウモリ?)や「悪魔の魚」(キプリノドン・ディアボリス)など、説明が曖昧だったり具体的すぎる場合、AIは非常に混乱してしまいます。 このため、ターゲット検出に大規模なモデルを使用する場合、特にオープンワールド (未知のシーン) のターゲット検出タスクでは、結果が期待したほど良くないことがよくあります。 さて、NeurIPS 2023 に含まれる論文によって、この問題がついに解決されました。 この論文では、マルチモーダル クエリに基づいたターゲット検出手法 MQ-Det を提案しています。入力に画像サンプルを追加するだけで、大規模モデルの物体検索の精度が大幅に向上します。 ベンチマーク検出データ セット LVIS では、下流のタスク モデルを微調整する必要がなく、MQ-Det は主流の検出大規模モデル GLIP の精度を平均約 7.8% 向上させ、また、ベンチマーク検出データ セット LVIS の精度も平均 6.3% 向上させます。 13 個のダウンストリーム タスクの小さなサンプルのベンチマーク。
