研發大模型的血液–萬字長文詳諦資料工程
研發大模型的血液–萬字長文詳諦資料工程
內容導讀
這篇內容深入探討了在研發領域中針對大型語言模型(LLMs)的資料工程。 強調了有效資料管理的重要性,以及利用領域自適應預訓練、監督微調和檢索增強生成等高級技術來提升LLMs在專業領域中的表現。 一個關鍵要點是AI BOMs的概念,透過與AI訓練資料和模型架構相關的元數據,提供透明度和風險評估。 這篇文章以其全面的方法來提升LLMs在研發中的可靠性和性能而脫穎而出,對從事人工智慧和機器學習領域的專業人士而言是一篇有價值的閱讀材料。
自動總結
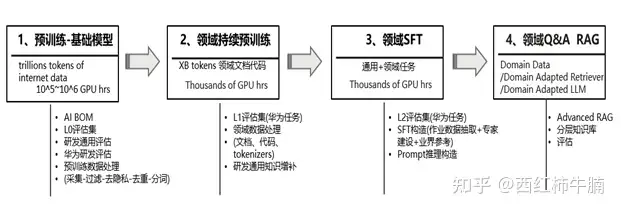
– 資料品質對模型效能和訓練效率至關重要。
– 預訓練和微調階段需要進行資料管理以增強模型效能和提高訓練效率。
– 預訓練階段需要使用通用文字和專用文字進行訓練,以獲得基本的語言理解和生成能力。
– 在預訓練資料中,需要進行品質過濾、去重、隱私去除和分詞等預處理步驟。
– 領域預訓練可以透過增量預訓練或領域自適應預訓練來提升模型表現。
– 微調階段需要設計指令格式來適應特定任務。
– RAG技術可以提高模型產生回應的品質。
– 推理階段需要進行提示工程來設計適合特定任務的提示策略。
– AIBOM的概念可以提高AI訓練資料的透明度和風險評估。
– SFT、RAG和微調可以同時使用,以提高模型效能和可靠性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相關文章
暫無評論...
AiWindVane 收集了來自全球的各種 AI 工具,包括全面的 AI 轉錄工具、AI 圖像工具、AI 視頻工具、AI 聲音工具、AI 編輯工具、AI 音樂工具、AI 設計工具和 AI 討論工具。 提供AI學習和開發常用網絡、框架和模型全表,支持和理解AI時間,並有效應用到工作和生活中。