2月2日のビッグモデル日報集

【2月2日のビッグモデル日報集】A16Zの最新AI洞察 | 2023年はAI動画元年、2024年も解決すべき課題はまだある; 設立2年、指導歴1年半経験: ベビー AI トレーナーが Science に掲載; 2B パラメータのパフォーマンスが Mistral-7B を超える: 壁面に面したインテリジェント マルチモーダル エンドサイド モデル オープンソース
大型模型にも泥棒がいる? パラメータを保護するには、大きなモデルを送信して「人間が判読できるフィンガープリント」を作成してください。
リンク: https://news.miracleplus.com/share_link/17446
大規模なモデルの事前トレーニングには膨大な量のコンピューティング リソースとデータが必要となるため、事前トレーニングされたモデルのパラメータは主要な機関が保護に重点を置く中核的な競争力と資産になりつつあります。 しかし、ソースコードを比較することでコードの盗用の有無を確認できる従来のソフトウェア知的財産保護とは異なり、事前学習モデルのパラメータの盗用を判断するには、次の2つの新たな問題が発生します。1) 事前学習モデルのパラメータ、特に数千億レベルのモデルのパラメータは通常、オープンソースではありません。 2) さらに重要なのは、事前トレーニングされたモデルの出力とパラメーターは、SFT、RLHF などの下流の処理ステップによって変化し、事前トレーニングを継続することです。 このため、モデルの出力またはモデル パラメーターに基づいて、モデルが別の既存のモデルに基づいて微調整されているかどうかを判断することが困難になります。 したがって、大規模なモデル パラメーターの保護は、効果的な解決策が存在しない新たな問題となります。 この目的を達成するために,上海交通大学のLin Zhouhan教授らのLumia研究チームは,人間が判読できる大型モデルのフィンガープリントを開発した.この方法は,モデルパラメータを開示する必要なく,各大型モデル間の祖先を効果的に識別することができる.

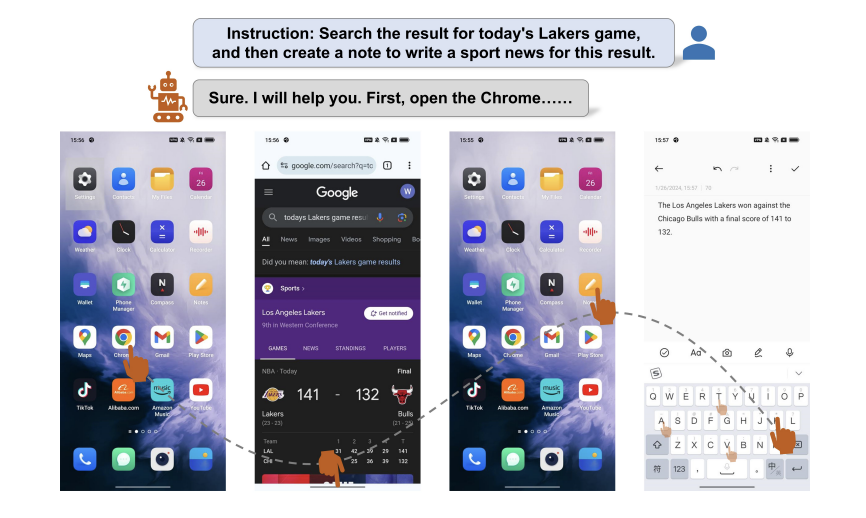
アリババの新しいエージェントは携帯電話で遊んでいます。彼は短いビデオにいいねをしたりコメントしたり、複数のアプリケーションで操作することを学びました
リンク: https://news.miracleplus.com/share_link/17447
携帯電話も操作できるスマートボディが新たにバージョンアップ! 新しいエージェントは、APP の境界を打ち破り、アプリケーション全体でタスクを完了できる、真のスーパー モバイル アシスタントになります。 例えば、バスケットボールの試合結果を指示に従って自ら検索し、試合状況に応じてメモに文章を書き込むことができる。 アリババの最新の論文では、新しい携帯電話制御エージェント フレームワークである Mobile-Agent が 10 個のアプリケーションで動作し、複数の APP にわたってユーザーによって割り当てられたタスクを完了できることが示されており、プラグ アンド プレイであり、トレーニングは必要ありません。 マルチモーダル大規模モデルに依存するため、操作プロセス全体は完全に視覚機能に基づいており、APP 用の XML 操作ドキュメントを記述する必要はありません。
代謝データセットの 4 つの指標は 94% ~ 98% に達し、西南交通大学チームは医薬品の研究開発を支援するマルチスケール グラフ ニューラル ネットワーク フレームワークを開発しました。
リンク: https://news.miracleplus.com/share_link/17448
医薬品開発の過程において、分子と代謝経路の関係を理解することは、新しい分子を合成し、薬物代謝メカニズムを最適化するために非常に重要です。 西南交通大学のYang Yan/Jiang Yongquan チームは、化合物と代謝経路を接続するための新しいマルチスケール グラフ ニューラル ネットワーク フレームワーク MSGNN を開発しました。 これは、特徴エンコーダー、サブグラフ エンコーダー、およびグローバル特徴プロセッサーの 3 つの部分で構成されており、それぞれ原子特徴、部分構造特徴、および追加のグローバル分子特徴を学習し、これら 3 つのスケール特徴により、モデルにより包括的な情報を与えることができます。 KEGG 代謝経路データセットに対するこのフレームワークのパフォーマンスは既存の手法よりも優れており、精度、精度、再現率、F1 はそれぞれ 98.17%、94.18%、94.43%、94.30% に達しています。 さらに、チームはグラフ拡張戦略も採用し、トレーニング セット内のデータ量を 10 倍に拡大し、モデルのトレーニングをより適切にしました。

A16Z の最新 AI 洞察 | 2023 年は AI ビデオ元年、2024 年にも解決すべき問題はまだある
リンク: https://news.miracleplus.com/share_link/17449
これは、A16Z パートナーの Justine Moore が発表した 2024 年の最新 AI ビデオ展望です。 Justine 氏は、2023 年が AI ビデオ分野にとって画期的な年になるだろうと述べました。 2023 年の初めには、公開されたテキストからビデオへのモデルは存在していませんでした。 わずか 12 か月後、数十のビデオ生成製品がすでにアクティブに使用されており、世界中の何百万ものユーザーがテキストまたは画像のプロンプトから短いクリップを作成しています。 これらの製品はまだ比較的限られており、生成されるほとんどのビデオの長さは 3 ~ 4 秒で、出力の品質はさまざまで、文字の一貫性などの問題はまだ解決されていません。 単一のテキスト プロンプト (または複数のプロンプト) を備えたピクサー レベルの短編映画を作成するには、まだ長い道のりです。 しかし、過去 1 年間にビデオ生成分野で私たちが目撃した進歩は、画像生成分野で A16Z で見られたものと同様に、私たちが大規模な変革の初期段階にあることを示唆しています。 私たちは、テキストからビデオへのモデルが継続的に改善され、画像からビデオやビデオからビデオへの派生テクノロジーが勢いを増しているのを目の当たりにしています。 このイノベーションの爆発を理解するために、A16Z はこれまでの最も重要な開発、注目すべき企業、そしてこの分野に残された基本的な疑問を追跡しています。

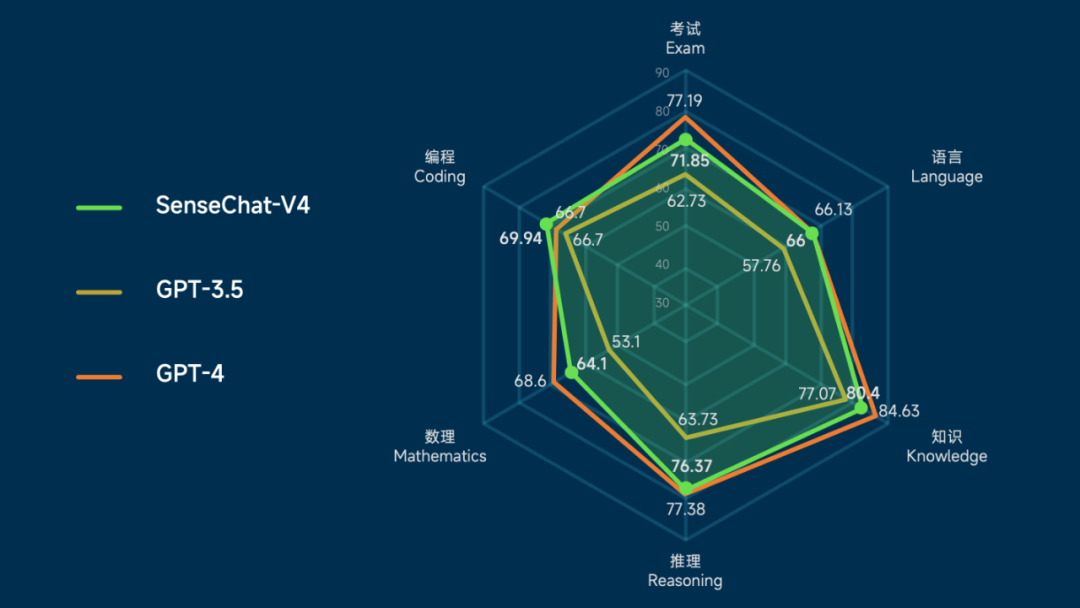
GPT-4 と比較して、SenseTime は 4.0 に大幅にアップグレードされ、マルチモーダル機能で主導権を握りました
リンク: https://news.miracleplus.com/share_link/17450
SenseTimeの大規模モデルシステム「RiRiXin SenseNova」は、言語機能とテキスト機能の両方が完全にアップグレードされ、低しきい値の実装ツールも付属したバージョン4.0を本日リリースしました。 新世代の SenseNova は、大規模な言語モデルやヴィンセント グラフ モデルなどで大幅なアップグレードが行われただけでなく、一部の垂直分野での機能が GPT-4 を超えています。また、新しいマルチモーダル大規模モデルがリリースされ、データ分析、医療、その他のシナリオ向けの新しいバージョン。これにより、大規模モデルの一般的な機能をより多くの分野に適用できるようになります。
2歳、指導歴1年半:ベビーAIトレーナーがサイエンスに登場
リンク: https://news.miracleplus.com/share_link/17451
チューリング賞受賞者のヤン・ルカン氏は公開インタビューで、現在のAIモデルの学習効率が人間の赤ちゃんと比べて低すぎると何度も言及した。 では、AI モデルに、赤ちゃんのヘッドマウント カメラが何を捉えているかを学習するよう依頼した場合、何が学習できるのでしょうか? 最近、サイエンス誌の論文で予備的な試みが行われました。 この研究では、データが限られている場合でも、AI モデルは 10 ~ 100 個の例から単語と視覚的指示対象の間のマッピングを学習でき、ゼロサンプルで新しい視覚的データセットに一般化し、マルチモーダルアライメントを達成できることがわかりました。 これは、今日の人工知能ツールを使用すると、幼児の視点から真の言語学習が可能であることを示しています。
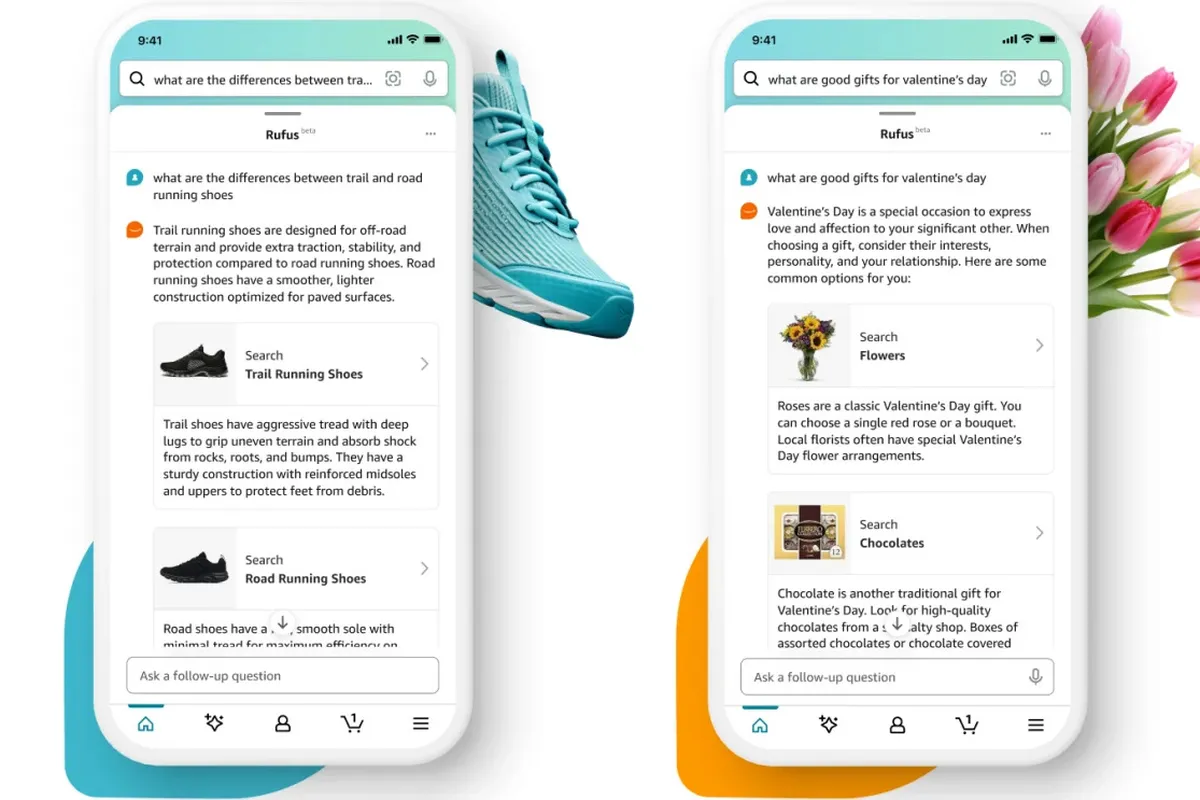
Amazon、人工知能ショッピングアシスタント「TRUfusJ」を発表
リンク: https://news.miracleplus.com/share_link/17452
アマゾンは、同社のマスコットであるコーギーにちなんで名付けられた「ルーファス」と呼ばれる人工知能ショッピングアシスタントを発売した。 チャットボットは Amazon の製品ライブラリ、顧客レビュー、Web からの情報に基づいてトレーニングされており、製品に関する質問に答えたり、比較を行ったり、推奨事項を提供したりできるようになりました。 Rufus はまだベータ版であり、今後数週間以内にさらに多くのユーザーに公開される前に、「一部の顧客」のみが利用できるようになります。
2B パラメータのパフォーマンスは Mistral-7B を超えます: 壁面インテリジェント マルチモーダル エンドサイド モデル オープンソース
リンク: https://news.miracleplus.com/share_link/17453
大規模なモデルは引き続き大容量化を目指していますが、最近では、最適化と展開でも成果を上げています。 Wall-Facing Intelligenceと清華NLP研究所は2月1日、主力エンドツーサイド大型モデル「Wall-Facing MiniCPM」を北京で正式に発表した。 新世代の大型モデルは「高性能小型スチールキャノン」と呼ばれ、端末の展開を直接取り入れており、クラス最強のマルチモーダル機能も備えています。 今回Face Wall Intelligenceが提案したMiniCPM 2Bパラメータ量はわずか20億であり、1Tトークンの厳選されたデータを使用してトレーニングされています。 これは、2018 年の BERT と同じレベルのパラメータを備えたモデルです。Wall-Facing Intelligence は、究極のパフォーマンスの最適化とその上でのコスト管理を実現し、このモデルが「跳躍してモンスターを倒す」ことを可能にします。 Face Wall Intelligence の共同創設者兼 CEO である Li Dahai 氏は、この新モデルを業界でよく知られたオープンソースの大型モデルである Mistral-7B と比較し、多くの主流の評価リストで MiniCPM 2B のパフォーマンスが後者を完全に上回りました。
