Big Model Daily (6 月 13 日)

[Big Model Daily (6 月 13 日)] ニュース: ① IDC の最新レポート、大手モデル メーカー 11 社が 7 つの主要な側面で競争、すべてを兼ね備えている唯一の企業はどこですか? ②安定性 Al オープンソース Stable Diffusion 3 Medium Vincent グラフ モデル; 論文: ①LLaMA-3 を使用して数十億のオンライン画像の記述を再追加するとどうなるでしょうか?投資と資金調達: Black Semiconductor はヨーロッパのチップ開発を促進するために 2 億 7,400 万米ドルを調達
IDC の最新レポートでは、大手モデル メーカー 11 社が 7 つの主要な側面で競争していることが示されています。すべてを兼ね備えているのは誰でしょうか?
https://news.miracleplus.com/share_link/29917
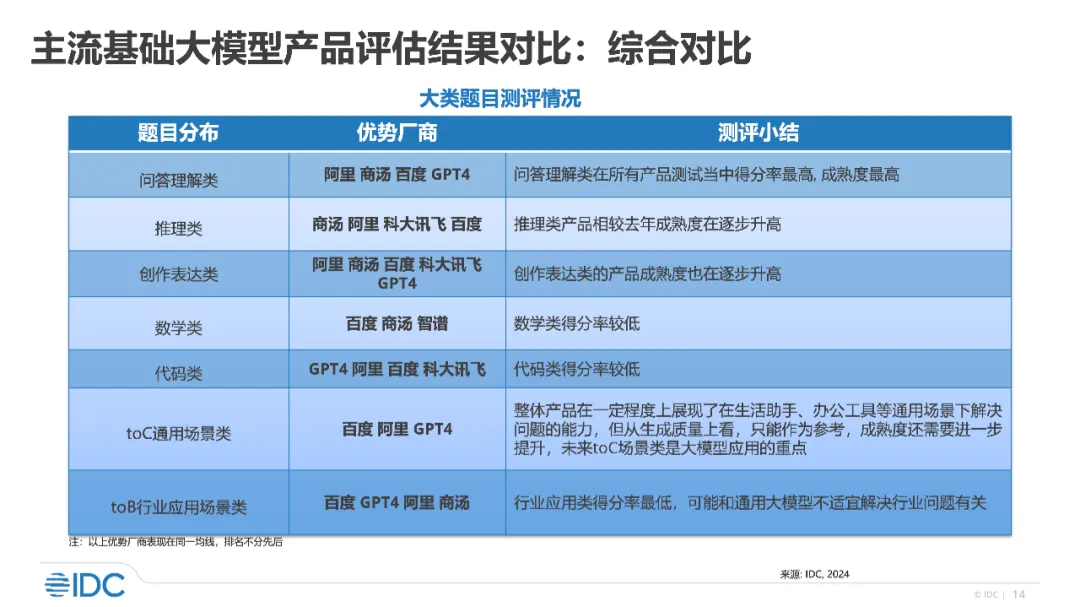
テスト問題が簡単すぎると、下手な生徒でも 100 点を獲得できます。 AI界において、常にトラフィックのCポジションにあった大型モデルの真のレベルをテストするには、どのような「テスト用紙」を使用する必要がありますか?大学の入試問題ですか?もちろん違います!さまざまなベンチマーク リストで 1 位になった人が最も強いと信じている人もいます。実際には、そうではない場合もあります。リストの「権威」が高いほど、戦略的にリストから削除されやすくなります。したがって、モデルの「強さ」は、特定のベンチマークで 1 位にランクされるだけではなく、複数の側面で優れたパフォーマンスを発揮できなければなりません。世界大手のインターナショナルデータコーポレーション(IDC)はこのほど、大型モデルメーカー11社の市場主流製品16製品を基本性能から7次元で評価した最新の大型モデル測定レポート「2024年中国大型モデル市場における主流製品の評価」を発表した。アプリケーションの機能を実際に測定します。報告書は、Baidu Wenxin の全体的な競争力がトップレベルにあり、製品能力が第一段階にあり、7 つの側面すべてにおいて有利なメーカーである唯一の企業であることを示しています。 Wen Xin Yi Yan と Wen Xin Yi Ge は、質問と回答の理解、推論、創造的な表現、数学、コーディングなどの基本的な能力と、toC の一般的なシナリオ カテゴリや toB などの応用能力を含む、7 つの主要な側面で優れた優位性を持っています。特定の業種。他の評価対象メーカーの中で、Alibaba は 6 つの利点を獲得し、OpenAI GPT-4 と SenseTime はそれぞれ 5 つの利点を獲得しました。
安定性 Al オープンソース 安定した拡散 3 中型 Vincent ダイアグラム モデル
https://news.miracleplus.com/share_link/29833
6 月 12 日の夜、人工知能スタートアップの Stability AI は、最新のテキストから画像への生成モデルである Stable Diffusion 3 Medium (SD3 Medium) の公式オープンソース リリースを発表しました。 Stable Diffusion 3 Medium には 20 億のパラメータが含まれており、これまでで最も先進的な Text-to-Image オープン モデルです。VRAM フットプリントが小さく、コンシューマ グレードの GPU やエンタープライズ グレードの GPU での実行に適したものになっています。

ソラレベルのプレイヤーがまた登場します!
https://news.miracleplus.com/share_link/29920
Sora を使用しないと本当に盗まれます。本日、サンフランシスコのスタートアップ Luma AI (切り札) が、新世代の AI ビデオ生成モデル Dream Machine を誰でも無料で利用できるようにしました。

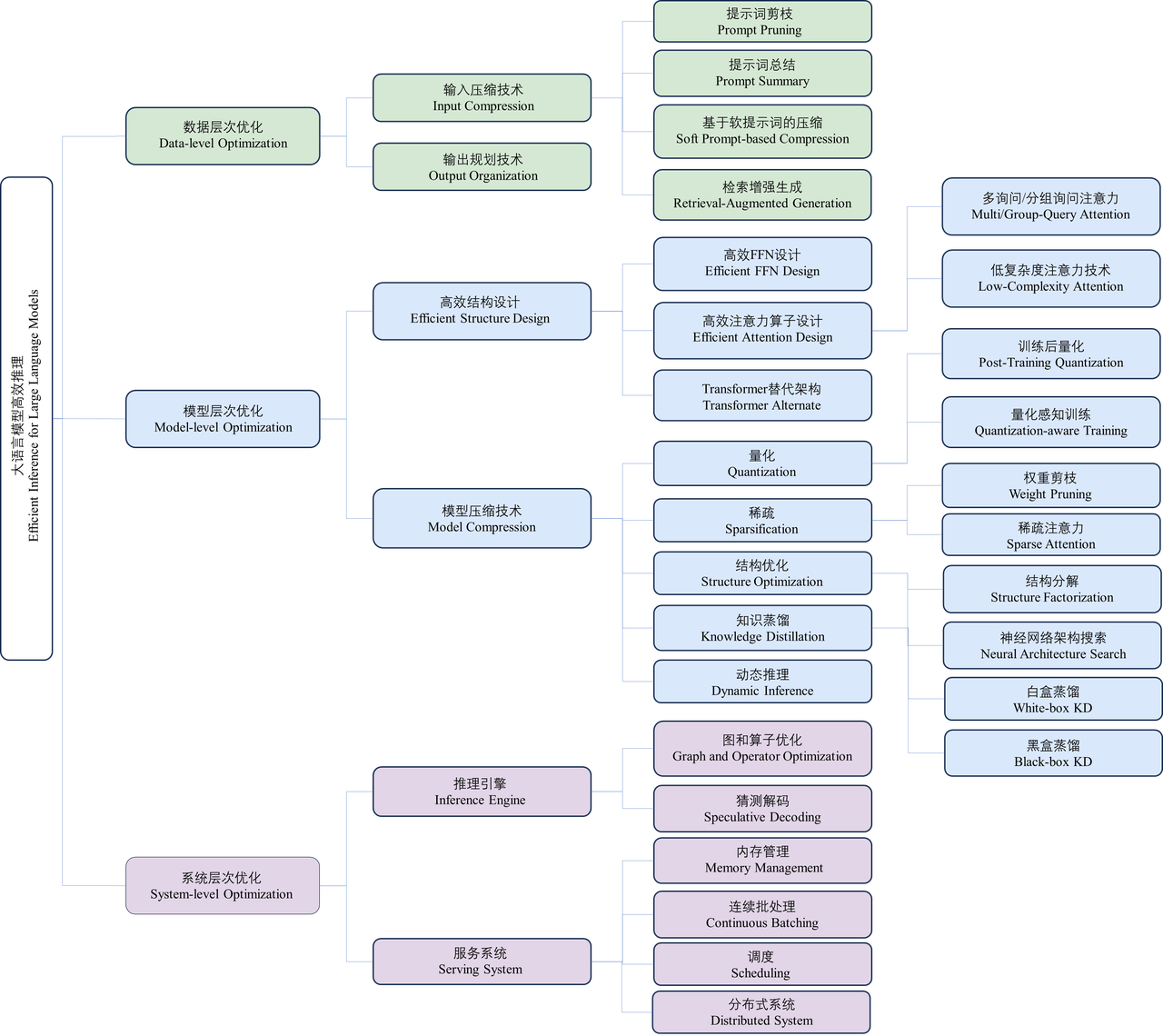
大規模モデルの効率的な推論に関する 10,000 語のレビュー: Wuwenxinqiong と清華大学および上海交通大学との最新の共同研究は、大規模モデル推論の最適化を包括的に分析しています
https://news.miracleplus.com/share_link/29921
近年、大規模言語モデル (LLM) は、さまざまな言語生成タスクにおける優れたパフォーマンスのおかげで、さまざまな人工知能アプリケーション (ChatGPT、Copilot などの開発) を促進してきました。 。)。ただし、大規模な言語モデルの適用は推論のオーバーヘッドが大きいため制限され、展開リソース、ユーザー エクスペリエンス、経済的コストに大きな課題が生じます。たとえば、推論用の 700 億のパラメーターを含む LLaMA-2-70B モデルを展開するには、少なくとも 6 枚の RTX 3090Ti グラフィックス カードまたは 2 枚の NVIDIA A100 グラフィックス カードが必要です。例として A100 グラフィックス カードに展開すると、モデルは 512 個の長さのチャンクを生成します。 . (トークン) シーケンスには 50 秒以上かかります。大規模な言語モデルの推論オーバーヘッドを最適化するための技術の設計に多くの研究努力が注がれており、モデルの推論レイテンシ、スループット、消費電力、ストレージ指標の最適化が多くの研究の重要な目標となっています。これらの最適化テクノロジーをより包括的かつ体系的に理解し、大規模言語モデルの導入実践と将来の研究に対する提案とガイダンスを提供するために、清華大学電子工学部、Wuwen Core Dome、Shanghai Jiao Tong の研究チームが協力しました。大学は、大規模言語モデルに関する研究を実施し、言語モデルの効率的な推論技術について、10,000 語のレビュー「大規模言語モデルの効率的な推論に関する調査」(LLM Eff-Inference) で包括的に調査および整理しました。現場での作業は 3 つのカテゴリに分類されます。 レイヤー (つまり、データ レイヤー、モデル レイヤー、システム レイヤー) を最適化し、関連する技術的な作業をレイヤーごとに紹介および要約します。さらに、この研究では、非効率的な大規模言語モデル推論の根本原因も分析し、既存の研究のレビューに基づいて、将来の効率的な推論の分野で注意を払うべきシナリオ、課題、ルートを深く調査します。研究者に将来の研究の方向性を提供します。
「AI+物理学の事前知識」、浙江大学および中国科学院の一般的なタンパク質-リガンド相互作用スコアリング手法が Nature サブジャーナルに掲載
https://news.miracleplus.com/share_link/29922
タンパク質は体内の繊細な鍵のようなもので、適切な鍵だけが治療への扉を開けることができるのは薬物分子です。科学者たちは、これらの「キー」と「ロック」の間の適合性、つまりタンパク質とリガンドの相互作用を予測する効率的な方法を探してきました。ただし、従来のデータ駆動型の手法は、リガンドとタンパク質の相互作用を実際に学習するのではなく、リガンドとタンパク質のトレーニング データを暗記する「暗記学習」に陥ることがよくあります。最近、浙江大学と中国科学院の研究チームは、異種グラフ ニューラル ネットワークを使用して物理的な事前知識を統合し、等変幾何学的空間におけるタンパク質-リガンド相互作用を特徴付ける EquiScore と呼ばれる新しいスコアリング方法を提案しました。 EquiScore は、複数のデータ拡張戦略と厳密な冗長性排除スキームを使用して構築された新しいデータセットでトレーニングされます。 2 つの大規模な外部テスト セットでは、EquiScore が他の 21 の方法と比較して常にトップに立っています。 EquiScore をさまざまなドッキング方法とともに使用すると、これらのドッキング方法のスクリーニング機能を効果的に強化できます。 EquiScore は、一連の構造類似体の活性をランク付けするタスクでも良好なパフォーマンスを示し、リード化合物の最適化を導く可能性を実証しました。最後に、EquiScore のさまざまな解釈可能性レベルが調査され、構造に基づいた医薬品設計にさらなる洞察が得られる可能性があります。
