8 月 27 日のビッグ モデル デイリー コレクション

[8 月 27 日のビッグ モデル デイリー コレクション] ニュース: OpenAI、Adobe、Microsoft がカリフォルニア州の AI コンテンツ透かし法案を支持、KDD 2024 の中国チームが輝かしいデビューを飾る、
OpenAI、Adobe、Microsoft がカリフォルニア州の必須 AI コンテンツ透かし法案を支持
リンク: https://news.miracleplus.com/share_link/38717
OpenAI、Adobe、Microsoftの大手テクノロジー企業3社は、テクノロジー企業にAI生成コンテンツのラベル付けを義務付けるカリフォルニア州の次期AB 3211法案への支持を表明した。この法案では、AIが生成した写真、ビデオ、オーディオのメタデータに透かしを追加することが義務付けられ、インスタグラムやXなどの大手オンラインプラットフォームにはAIが生成したコンテンツを一般の視聴者が理解できる方法で識別することが義務付けられる。
背景情報: AB 3211 の初期バージョンは、Adobe や Microsoft などの大手ソフトウェア メーカーを代表する業界団体によって反対され、同法案は「実行不可能」で「負担がかかりすぎる」と考えられていました。しかし、法案が修正されると、これらの企業は態度を変え、支持を表明した。これらのテクノロジー企業は、広く使用されている AI コンテンツ識別標準の作成に貢献した Content Provenance and Authenticity Alliance (C2PA) のメンバーです。
KDD2024中国チームが輝かしいデビューを飾る
リンク: https://news.miracleplus.com/share_link/38718
KDD 2024 カンファレンスはスペインのバルセロナで開催され、データサイエンス分野における最新の技術成果を紹介するために世界中から一流の学者や企業の代表者が集まりました。中国チームの成績は好調で、清華大学、アリババ、リスAIなどの大学や企業の研究結果も含まれており、データマイニング分野における中国の主導的地位を示している。
このカンファレンスでは、データマイニング、知識発見、予測分析などの複数の分野が取り上げられ、教育業界や金融業界における新興テクノロジーの応用傾向について深く議論されました。 Squirrel AI は中国のテクノロジー企業を代表し、生成人工知能と教育テクノロジーのイノベーションの分野で詳細な共有を実施しました。
カンファレンスのハイライトには、基調講演と円卓会議が含まれ、専門家が大規模言語モデル (LLM) の認知機能、AI と自然環境の共生、教育における AI の応用などの最先端のトピックについて議論しました。特に、人工知能教育分野における中国チームの実践と探求は、広く注目され、評価されています。

バイトが大型模型研究所を設立
リンク: https://news.miracleplus.com/share_link/38719
ByteDance は大規模モデル研究機関の設立を密かに準備しており、AI のトップ人材を精力的に採用していることから、大規模モデルが同社の戦略的焦点となっていることがわかります。この件に詳しい関係者は、外部のAI専門家が研究所に加わったことを明らかにした。さらに、Yuanxuzhi Technologyの創設者であるQin Yujia氏とYuanzhiyiwuの中心メンバーであるHuang Wenhao氏もByteの大規模モデルチームに加わっているが、彼らが新設の研究機関に所属しているかどうかはまだ明らかではない。
ByteDanceは昨年から大型モデルに関する進捗状況を段階的に公開し、独自に開発した基盤となる大型モデル「Skylark」とAI対話製品「Doubao」をローンチし、AIアプリケーションに焦点を当てた社内プロジェクト「Flow」を設立した。 AI製品が国内外で拡大を続ける中、ByteDanceは主に社内の事業部門に依存するこれまでの慣行を変え、外部からより多くの人材を導入し始めている。 AI 分野の上級専門家として、Huang Wenhao 氏は Microsoft Research Asia と Zhiyuan Research Institute で広範な研究と応用の経験を持ち、今回 Byte に加わることで、彼の大規模なモデル チームの強みがさらに強化されます。

GoogleのAIスタートアップ企業のジレンマ
リンク: https://news.miracleplus.com/share_link/38720
この記事では、元 Google 従業員によって設立された AI スタートアップ企業が、大手テクノロジー企業との競争に直面する際に直面するジレンマについて考察します。 Google ベースの AI スタートアップの多くは、設立からわずか数年で買収されたり、多くの課題に直面したりしています。その理由としては、学歴のある創業者の事業運営経験の不足、AI 開発コストの高さ、投資家の態度の変化などが挙げられます。記事ではまた、買収対象と考えられる複数のAI企業を挙げ、現状と直面する課題を分析している。

大型モデルのチップがホットチップサミットに登場
リンク: https://news.miracleplus.com/share_link/38721
2024 Hot Chips カンファレンスでは、AI チップが焦点となりました。 IBM、FuriosaAI、その他の企業は、革新的な AI チップ、特に大規模モデル推論用に設計された FuriosaAI の第 2 世代データセンター AI チップ RNGD をデモしました。 RNGD は TSMC の 5nm プロセスを使用し、高いエネルギー効率、プログラマビリティ、256MB のオンチップ SRAM を備えており、特に Llama 3.1 などの大規模な言語モデルを実行する場合、そのパフォーマンスは現在の主要な GPU を上回ります。 IBM は、AI アクセラレータ Spyre を内蔵した新世代の Telum II プロセッサをリリースし、メインフレーム プロセッサ上で AI モデルを実行する機能も実証しました。 FuriosaAI はエネルギー効率とコストの面で自社チップの利点を強調し、データセンターにおける大規模 AI 推論の実際的な問題を解決すると述べています。 TCP アーキテクチャと Tensor Contraction Processor (TCP) テクノロジーは RNGD の中核であり、効率的なデータ再利用とコンピューティング機能を提供し、従来の GPU に代わる強力な競争相手となります。
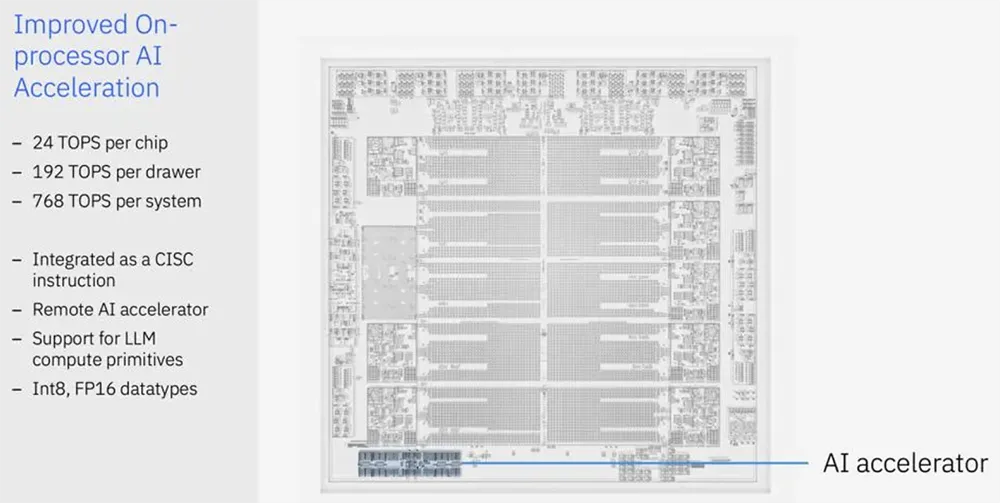
HotChip2024-Day1:AI アクセラレータ チップ
リンク: https://news.miracleplus.com/share_link/38722
HotChip 2024 の初日、大手非クラウド メーカーが AI アクセラレータ チップをデモしました。 Nvidia の Blackwell は主にマイクロアーキテクチャの詳細を誇っており、開示していません。 AMD MI300XやIntel Gaudi 3のデモが行われ、Tenstorrent、FuriosaAI、BRCMなども興味深い内容でした。
主なハイライト:
1. AMD MI300X: Infinity Fabric Advanced Package を使用して高帯域幅の相互接続を実現します。 FP8 コンピューティングをサポートし、主に推論および FineTune アプリケーション用に 256MB Infinity Cache を提供し、Nvidia H100 に対するベンチマークを実行します。
2. Intel Gaudi 3: シストリック配列アーキテクチャを継続し、行列乗算エンジンは 256×256 であり、非同期コンピューティング機能を向上させるために AGU が追加されています。 RoCE 相互接続を導入し、21 個の Fullmesh ScaleUP と 3 個の ScaleOut をサポートします。
3. SambaNova SN40L: DDR を拡張することでメモリ容量を増加し、マルチモーダル推論をサポートします。新世代アーキテクチャは、PCU と PMU を組み合わせて Tensor 処理能力を向上させ、メッシュ/リング ハイブリッド相互接続構造を採用しています。
4. Furiosa: アインシュタインの和記号に基づいて計算を実行する新しいコンセプトの Tensor Contraction Processor を発表しました。PCIe カードは 48 GB HBM をサポートし、2D メッシュ オンチップ ネットワークを使用します。
5. Tenstorrent: 3 ブロックのマイクロアーキテクチャ設計を採用し、非同期メモリ アクセスと複数のデータ アクセス プリミティブをサポートし、標準のイーサネット相互接続をサポートし、あらゆるトポロジに拡張します。
6. Nvidia Blackwell: マイクロアーキテクチャについては詳しく紹介されませんでしたが、コンピューティング規模が 2 倍になり、FP4 フォーマットが引き続き推進されると述べられました。 NV-HBI による 10TB/s の相互接続の達成により、複雑な液体冷却システムが実証されました。
7. IBM Telum 2: DPU と AI アクセラレーターを統合して、より強力なコンピューティング機能とデータ送信機能を提供する新世代のメインフレーム プロセッサー。
全体として、AI アクセラレータ チップの開発傾向の多様化は明らかであり、各メーカーは推論、FineTune、メモリ拡張、相互接続技術で画期的な進歩を遂げています。

Nexa AI との対話: 1995 年生まれのスタンフォード大学の学生 2 人が GPT-4o より 4 倍高速な小型モデルを構築
リンク: https://news.miracleplus.com/share_link/38723
Nexa AI は、スタンフォード大学の卒業生 2 名によって設立された新興企業で、「Hugging Face のクライアント側バージョン」を構築することを目標に、効率的な小型モデルの開発に重点を置いています。同社が開発した小型モデル「Octopus v2」は、パラメータ数5億個でGPT-4oの4倍の推論速度を実現し、関数呼び出し精度98%以上とGPT-4と同等の性能を実現した。同社はすぐに AI 業界の注目を集め、多くの有名企業顧客と契約し、シードラウンドで 1,000 万米ドルを超える資金調達を受けました。
Nexa AI の新製品 Octopus v3 はマルチモーダル機能を備え、さまざまなエッジ デバイスで効率的に実行でき、テキストと画像の入力をサポートします。同社は最近、自己研究やその他の高度なモデルを統合する包括的なエンドサイド AI 開発プラットフォーム「モデル ハブ」を立ち上げ、開発者にローカル展開のための柔軟なソリューションを提供し、完全なエンドサイド AI エコシステムを構築することを目指しています。
創設者は、小型モデルには速度、コスト、プライバシー保護の点で利点があり、ほとんどの実際的な問題を解決できると信じています。 Nexa AI は、革新的な Functional Token テクノロジーを通じて小規模モデルの関数呼び出しの問題を解決し、そのパフォーマンスが GPT-4o を超えることを可能にします。大手メーカーとの競争に直面する中、Nexa AI は技術的優位性とプラットフォーム戦略による差別化を追求し、デバイスサイド AI 分野のリーダーとなることを目指しています。
