11月7日大模型日報合輯

【11月7日大模型日報合輯】特別刊! OpenAI開發者大會奇績日報團隊總結
OpenAI開發者大會奇績日報團隊總結
一句話總結
OpenAI正在成為AI時代的蘋果:創造了AI需求,閉源生態,GPT store,以及正在開發的硬體…
GPT-4 Turbo:更快,更長,更便宜,多模態,客製化
具體地:
* API呼叫放開速度限制,速度翻倍,並支援進一步設置
* 推出GPT-4 Turbo,支援128K上下文,大概300多頁文檔,之前為32K
* 降低GPT-4 Turbo的價格,投入比GPT-4便宜3倍,產出便宜2倍,分別為0.01美元和0.03美元
* GPT 4 Turbo現在可以透過API接受影像作為輸入, 可以產生字幕, 分類和分析
* GPT4開放微調,讓公司客製化每個步驟並成專屬
其它一些細節:
* 更好的 JSON/函數呼叫。
* 內建 RAG,將訓練資料更新至2023 年 4 月截止日期
* GPT3.5 支援16k
* 目前,Dall-E 3、GPT-4V 和 TTS 模型均已納入 API
* Whisper V3 已開源(即將在 API 中推出)
GPT store:或會成為下一個Apple store?
之前ChatGPT推出的插件商城受歡迎程度較為一般,不知道這次能否徹底引爆用戶需求。
重點:無程式碼搭建個人agent,支援與他人分享並從中獲利。
GPT名字是想說這是ChatGPT 的自訂版本,使用者為他的特定任務創建定製版本的 ChatGPT 無需編寫任何程式碼行。
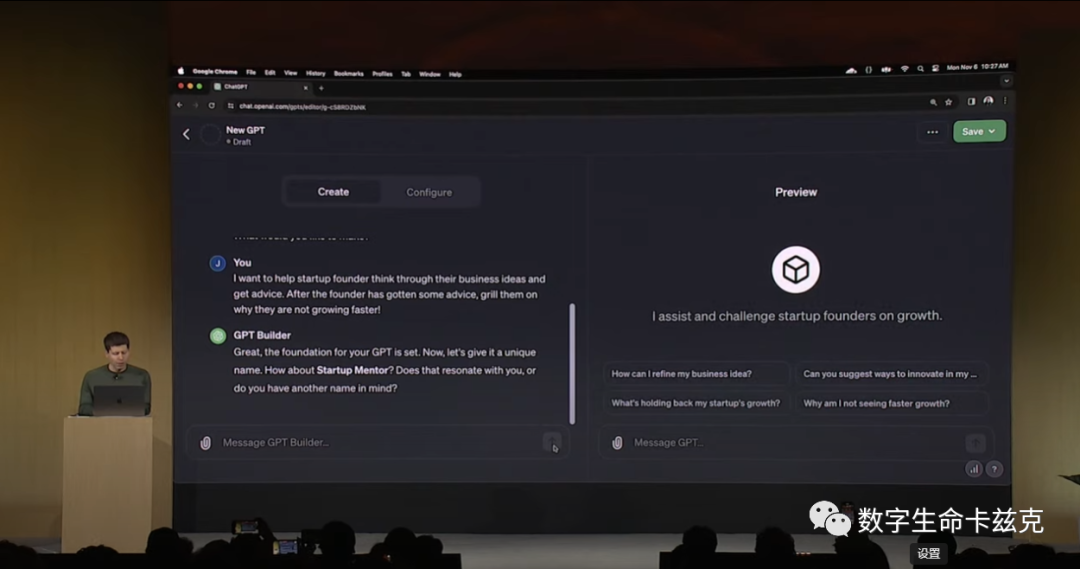
現場實際演示:
而且用戶做完的GPTs,還可以跟朋友分享,本月晚些時候,OpenAI將推出 GPT 商店,甚至還可以根據使用你創作的 GPT 的人數來賺錢。
使用者可以將GPT 連接到 API 以執行任務,例如管理資料庫、電子郵件、發送簡訊等等。

長上下文:
國內很多模型都在做長上下文,當然現在做長上下文也很容易,就是多一個微調的步驟。 但能容納長上下文不代表能利用好長上下文:無法正確召回相關細節,跨越文章做出推理,此外部署也是一大難題。
可控性:
雖然語言模型以其多元能力而驚艷世人,落地時真正需要的還是可控性和事實性,例如穩定生成 JSON 的能力,這也是此次更新重點介紹的。 其實作可能是對 decoding 進行限制,保證模型只按照 JSON 格式進行生成,也有可能進行過微調 。 JSON 格式不保證依照 schema 產生。
第二點是可控輸出,可以依照 seed 重現內容。
Sam 提到 Logprob 又回來了。 Logprob 有利於更細緻地操控語言模型的輸出,例如給補全評分,根據可能性判斷是否需要召回等。 可以看到 OpenAI 的確吸取了開發者的回饋。
Is `logprobs` being deprecated, or will it eventually be available for newer models? – API – OpenAI
Agent 推理:
OpenAI 所展示的 Agent 使用了 Code 與 natural language 混合的方式來進行推理。 這是 Agent 目前來說比較合理的推理形態。 Code 能夠精確計算,而natural language 能傳達意圖並方便人們驗證與理解。
可以推算 Code Interpreter 的一個用途就是收集這種自然語言和程式碼互相交織的推理內容。

多模態:
OpenAI 打通了文字和圖片,文字和語音,當然兩者作用不太一樣。 圖片已經可以用於生成,但是語音仍然主要服務於互動。
AIGD 會有大發展,Design2Code 這個環節被打通了,無論是直接使用 GPT-4v 還是使用 GPT-4v 收集數據,開發軟體的效率將會大大提升。
RAG:
OpenAI 開放了 Assistant API
此外每個 Assistant 最多只能處理 20 個文件,這個限制非常大。
根據推特上的試用,OpenAI 的RAG 策略是:
1. 文字分塊採用依照 \n 分割的方式
2. 召回策略上可能沒有問題分解,但返回文字區塊數量有變化;
3. utf-8 處理有問題;
當然 GPT-4v 對於處理PDF 有一定優勢。

對 Startup 的可能影響:
Prompt 和簡單 Rag 的淺層個人化不用玩了,平台幹這種事非常適合。 jiayuan 已經要開始 pivot 了。
深層個人化,包括model based 等複雜召回策略,與環境有複雜交互,對模型有調整的 Agent,短期內不會被取代,反而可能活得更好。 淺層個人化的市場很大,很吸引用戶,而且好做,對平台來說價值足夠高;過於垂直領域的市場對平台來說成本還是太高,不到山窮水盡不會啃這塊市場,而 到那時好的startup 應當能建立起壁壘,無論是模型或資料。
此外 OpenAI 作為平台能夠用這種淺層個人化建立使用者認知。 使用者如果感到需求不會滿意自然會尋求更垂直的服務。
具體而言,Sweep 這類 Agent 應該會活得更好,因為 GPT-4 也更便宜了。
一些細節:
1. 不拿 API 資料訓練模型是很弱的限制(Jack表示不信),透過 API 了解資料的分佈更有價值,能夠根據這個方向來收集和合成新的資料;
2. 請 Satya 的這個舉動很有意思,可能是為了向外界證實兩者的關係仍牢靠;
思考:AI的下一個載體是?
這次開發者大會來看,ChatGPT的功能已經是十分的強大,網頁的載體我認為已經不再適合承載AI。 或許OpenAI真的要開發一個屬於自己的OS系統,在系統層面部署AI才是更好的選擇。
Reference:
https://openai.com/blog/new-models-and-developer-products-announced-at-devday