2月18日-19日大模型日報合輯

【2月18日-19日大模型日報合輯】後Sora時代,CV實務工作者如何選擇模型? 卷積還是ViT,監督學習還是CLIP範式;揭秘Sora技術路線:核心成員來自伯克利,基礎論文曾被CVPR拒稿;離開OpenAI待業的Karpathy做了個大模型新項目,Star量一日破千;英偉達 首次公開目前最快AI超算:搭載4608個H100 GPU
後Sora時代,CV從業人員如何選擇模型? 卷積還是ViT,監督學習還是CLIP範式
連結:https://news.miracleplus.com/share_link/18656
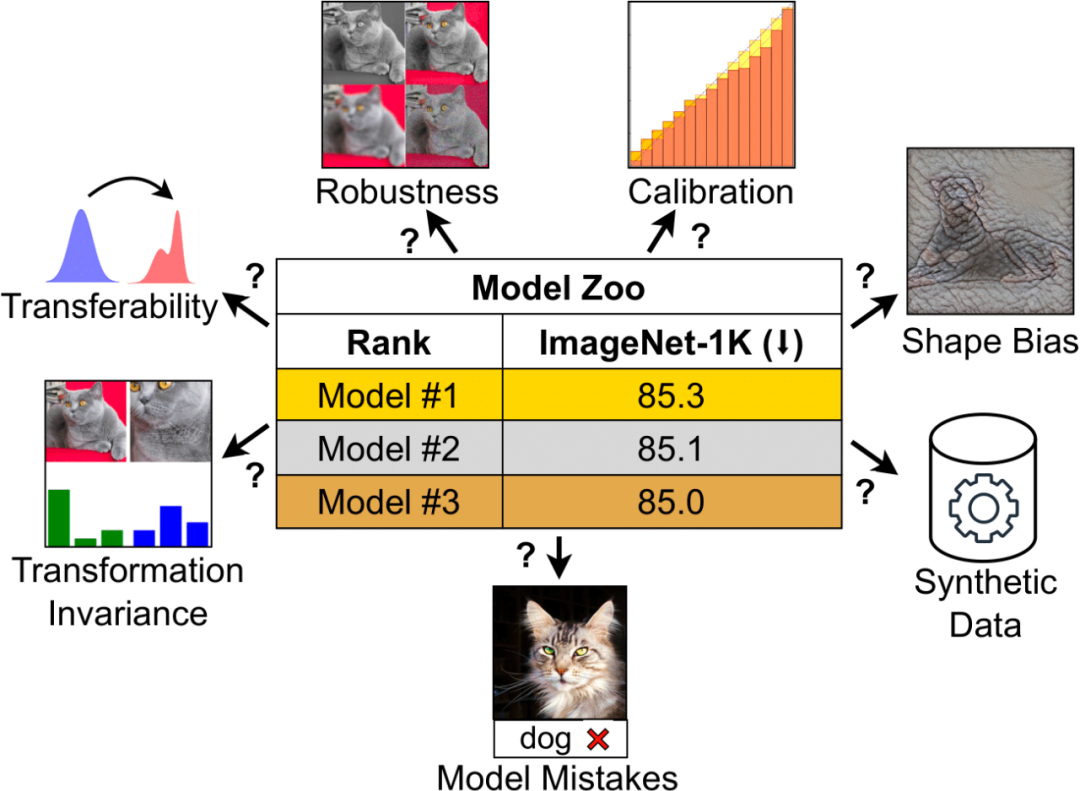
一直以來,ImageNet 準確度是評估模型效能的主要指標,也是它最初點燃了深度學習革命的火種。 但對於現今的計算視覺領域來說,這項指標正變得越來越不「夠用」。 因為電腦視覺模型已變得越來越複雜,從早期的 ConvNets 到 Vision Transformers,可用模型的種類已大幅增加。 同樣,訓練範式也從 ImageNet 上的監督訓練發展到自監督學習和像 CLIP 這樣的圖像 – 文字對訓練。 ImageNet 並不能捕捉到不同架構、訓練範式和資料所產生的細微差別。 如果僅根據 ImageNet 準確率來判斷,具有不同屬性的模型可能看起來很相似。 當模型開始過度擬合 ImageNet 的特異性並使準確率達到飽和時,這種限制就會變得更加明顯。 CLIP 就是個值得一提的例子:儘管 CLIP 的 ImageNet 準確率與 ResNet 相似,但其視覺編碼器的穩健性和可遷移性要好得多。 這些問題,為領域內的從業人員帶來了新的困惑:如何衡量一個視覺模型? 又如何選擇適合自己需求的視覺模型? 在最近的一篇論文中,MBZUAI 和 Meta 的研究者對這個問題進行了深入討論。
讓視覺語言模型搞空間推理,Google又整新活了
連結:https://news.miracleplus.com/share_link/18657
視覺語言模型 (VLM) 已經在廣泛的任務上取得了顯著進展,包括圖像描述、視覺問答 (VQA)、具身規劃、動作識別等等。 然而大多數視覺語言模型在空間推理方面仍然存在一些困難,例如需要理解目標在三維空間中的位置或空間關係的任務。 關於這個問題,研究者常常從「人類」身上獲得啟發:透過具身體驗和進化發展,人類擁有固有的空間推理技能,可以毫不費力地確定空間關係,例如目標相對位置或估算距離和 大小,而無需複雜的思考鏈或心理運算。 這種對直接空間推理任務的熟練,與當前視覺語言模型能力的限制形成鮮明對比,並引發了一個引人注目的研究問題:是否能夠賦予視覺語言模型類似於人類的空間推理能力? 最近,Google提出了一個具備空間推理能力的視覺語言模式:SpatialVLM。

100萬token,一次能分析1小時YouTube視頻,「大世界模型」火了
連結:https://news.miracleplus.com/share_link/18658
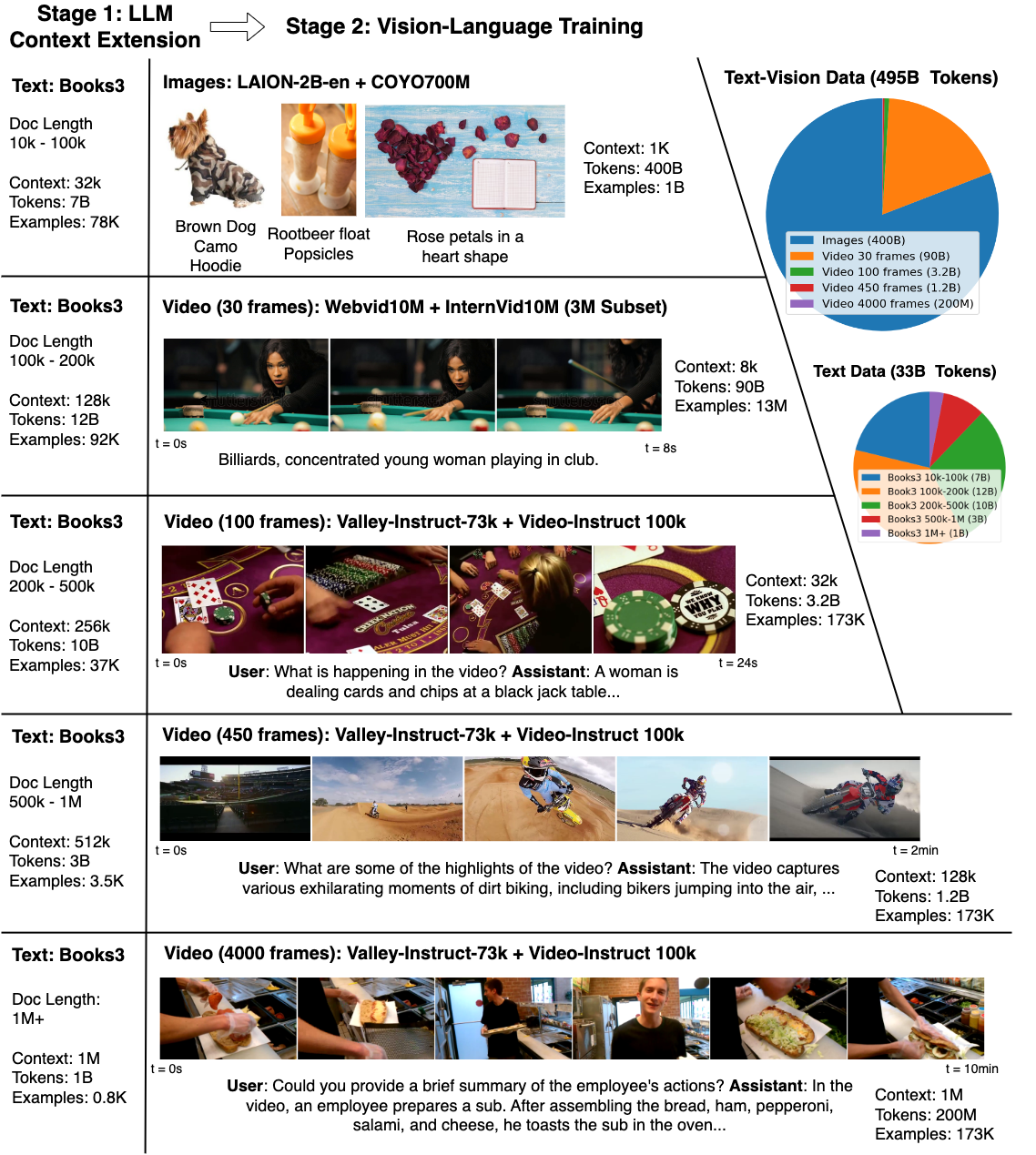
不只 Sora,現如今大模型雖然發展迅速,然而其自身也存在缺點,例如在現實世界中不容易用語言描述的內容,模型理解起來非常困難,又比如這些模型難以處理複雜的長程任務。 視訊模型的出現在一定程度上緩解了這個問題,其能提供語言和靜態圖像中所缺少的時間信息,這種信息對 LLM 非常有價值。 隨著技術的進步,模型開始對文本知識和物理世界有了更好的理解,從而幫助人類。 然而,由於記憶體限制、計算複雜性和有限的資料集,從數百萬個影片和語言序列的 token 中進行學習挑戰巨大。 為了回應這些挑戰,來自UC 伯克利的研究者整理了一個包含各種影片和書籍的大型資料集,並提出了大世界模型( Large World Model ,LWM),利用RingAttention 技術對長序列進行可擴展訓練, 逐漸將上下文大小從4K 增加到1M token。
Windows、Office直接上手,大模型智慧體操作電腦
連結:https://news.miracleplus.com/share_link/18659
當我們談到 AI 助理的未來,很難不想起《鋼鐵人》系列中那個令人炫目的 AI 助手賈維斯。 賈維斯不僅是東尼・史塔克的得力助手,更是他與先進科技的溝通者。 如今,大模型的出現顛覆了人類使用工具的方式,我們或許也離這樣的科幻場景又更近了一步。 想像一下,如果一個多模態 Agent,能夠直接像人類一樣透過鍵盤和滑鼠直接操控我們身邊的電腦,這將是多麼令人振奮的突破。 近期,吉林大學人工智慧學院發布了一項利用視覺大語言模型直接控制電腦 GUI 的最新研究《ScreenAgent: A Vision Language Model-driven Computer Control Agent》,它將這一想像映射進了現實。 這項工作提出了 ScreenAgent 模型,首次探索在無需輔助定位標籤的情況下,利用 VLM Agent 直接控制電腦滑鼠和鍵盤,實現大模型直接操作電腦的目標。 此外,ScreenAgent 透過「計劃-執行-反思」的自動化流程首次實現對 GUI 介面的連續控制。 這項工作是對人機互動方式的一次探索和革新,同時開源了具備精準定位資訊的資料集、控制器、訓練程式碼等。
揭秘Sora技術路線:核心成員來自伯克利,基礎論文曾被CVPR拒稿
連結:https://news.miracleplus.com/share_link/18660
最近幾天,據說全世界的創投機構開會都在大談 Sora。 自去年初 ChatGPT 引發全科技領域軍備競賽之後,已經沒有人願意在新的 AI 生成視訊賽道上落後了。 在這個問題上,人們早有預判,但也始料未及:AI 生成視頻,是繼文本生成、圖像生成以後技術持續發展的方向,此前也有不少科技公司搶跑推出自己的視頻生成技術 。 不過當 OpenAI 出手發布 Sora 之後,我們卻立即有了「發現新世界」的感覺 —— 效果和之前的技術相比高出了幾個檔次。 這次Sora的參與者中,已知的核心成員包括研發負責人 Tim Brooks、William Peebles、系統負責人 Connor Holmes 等。 這些成員的訊息也成為了眾人關注的焦點。
離開OpenAI待業的Karpathy做了個大模型新項目,Star量一日破千
連結:https://news.miracleplus.com/share_link/18661
過去幾天,OpenAI 非常熱鬧,先有 AI 大牛 Andrej Karpathy 官員離職,後來有影片生成模式 Sora 撼動 AI 圈。
在宣布離開OpenAI 之後,Karpathy 發推表示「這周可以歇一歇了。但是,有眼尖的網友發現了Karpathy 的新項目——minbpe,致力於為LLM 分詞中常用的BPE(Byte Pair Encoding, 字 節對編碼)演算法創建最少、乾淨以及教育性的程式碼。僅僅一天的時間,該專案的GitHub 標星已經達到了1.2 k。

Sora到底懂不懂物理世界? 一場腦力激盪正在AI圈大佬間展開
連結:https://news.miracleplus.com/share_link/18662
Sora 到底是不是實體引擎甚至是世界模型? 圖靈獎得主 Yann LeCun、Keras 之父 Francois Chollet 等人正在深入探討。 和以往只能產生幾秒鐘影片的模型不同,Sora 把生成影片的長度一下子拉長到 60 秒。 而且,它不僅能了解使用者在 Prompt 中提出的要求,還能 get 到人、物在物理世界中的存在方式。

融資超10億美金,AI公司「月之暗面」獲紅杉、小紅書、美團、阿里新一輪投資
連結:https://news.miracleplus.com/share_link/18663
AI新創公司「月之暗面」近期已完成新一輪超10億美金融資,投資人包括紅杉中國、小紅書、美團、阿里,老股東跟投。 月之暗面的上一輪融資為2023年獲得的超2億美金融資,投資方包括紅杉中國、真格基金等。 本輪融資後,月之暗面估值已達約25億美金,為國內大模型領域的頭部企業之一。

祖克柏最新對談:智慧型手機不會消失,AR 會是主流行動運算設備,XR 則是桌上型運算設備,生成式 AI 實現人機交流
連結:https://news.miracleplus.com/share_link/18664
Meta 創辦人&CEO Mark Zuckerberg 在上週參加了 Morning Brew 的專訪。 在訪談中,Mark 表示自己相信 AI 和 AR 技術將在未來改變我們的工作方式、生活方式和社交互動。 小扎認為AR 智慧眼鏡將是下一代運算的手機,在路上使用的運算平台,而XR 頭戴裝置可能是下一代的電腦或電視螢幕,你會有更大的螢幕;對大多數人來說 ,手機可能是更重要的設備,眼鏡可能會成為更重要和更普遍的東西,但它們兩者都是有意義的。

Sora 證明馬斯克的是對的,但特斯拉和人類可能都輸了
連結:https://news.miracleplus.com/share_link/18665
Sora 推出,馬斯克可能是心情最複雜的一個。 不僅因為其本人與 OpenAI 早年的糾葛,更因為 Sora 實現的其實是特斯拉早幾年間一直在探索的方向。 2 月18 日,馬斯克在科技主播@Dr.KnowItAll 一主題為「OpenAI 的重磅炸彈證實了特斯拉的理論」的影片下留言,稱「特斯拉已經能夠用精確物理原理製作真實世界 影片大約一年了」。 隨後他在 X 上轉發了一條 2023 年的視頻,內容是特斯拉自動駕駛總監 Ashok Elluswamy 向外界介紹特斯拉如何用 AI 模擬真實世界駕駛。 影片中,AI 同時生成了七個不同角度的駕駛視頻,同時只需要輸入「直行」或「變換車道」這樣的指令,就能讓這七路視頻同步變化。

英偉達首次公開目前最快AI超算:搭載4608個H100 GPU
連結:https://news.miracleplus.com/share_link/18666
近日,英偉達首次向外界公佈了其最新的面向企業的AI超級電腦Eos,同時也是英偉達目前速度最快的AI超級電腦。 據介紹,Eos共配備了4608個英偉達H100 GPU,同時還配備了1152個英特爾Xeon Platinum 8480C處理器(每個CPU有56個核心)。 Eos也採用了英偉達Mellanox Quantum-2 InfiniBand技術,資料傳輸速度高達400 Gb/s,對訓練大型AI模型和系統擴展至關重要。
