大模型日報(6月13日)

【大模型日報(6月13日)】資訊:①IDC最新報告,7大維度11家大模型廠商比拼,唯一全優是誰? ②Stability Al開源Stable Diffusion 3 Medium文生圖模型;論文:①如果我們用LLaMA-3重新添加數十億張網路圖片的描述會怎麼樣?投資資金:Black Semiconductor 融資2.74億美元以推動歐洲晶片發展
IDC最新報告,7大維度11家大模型廠商比拼,唯一全優是誰?
https://news.miracleplus.com/share_link/29917
如果考試題太簡單,學渣也能拿一百昏。在 AI 圈,我們應該拿怎樣的「考卷」來檢驗一直處於流量 C 位的大模型的真實水準?是高考題嗎?當然不是!也有些人認為,在各種 Benchmark 榜單上,誰排第一誰最強。其實並非如此,有時候,越「權威」的榜單就越容易被策略性刷榜。因此,模型的「強」不能只是在某個 Benchmark 上排名第一,而是要在多個維度上都很能打。近日,全球領先的國際數據公司(IDC) 最新發布的大模型實測報告《中國大模型市場主流產品評估,2024》從基礎能力到應用能力7 大維度對11 家大模型廠商的16 款市場主流產品進行實測。報告顯示,百度文心大模型整體競爭力位於領先水平,產品能力處於第一梯隊,是唯一在 7 大維度上均為優勢廠商的企業。文心一言、文心一格在問答理解類、推理類、創作表達類、數學類、代碼類等基礎能力,toC 通用場景類、toB 特定行業類等應用能力等7 大維度均具備領先優勢。其他評測廠商中,阿里獲 6 項優勢維度,OpenAI GPT-4 和商湯分獲 5 項。

Stability Al開源Stable Diffusion 3 Medium文生圖模型
https://news.miracleplus.com/share_link/29833
6月12日晚間消息,人工智慧新創公司Stability AI宣布正式開源發布其最新的文本到圖像生成模型Stable Diffusion 3 Medium (SD3 Medium)。 Stable Diffusion 3 Medium 包含 20 億個參數,是 StabilityAI迄今為止最先進的文本到圖像開放模型,更小的 VRAM 佔用空間旨在使其更適合在消費級 GPU 以及企業級 GPU 上運行。

又一Sora級選手來炸街!
https://news.miracleplus.com/share_link/29920
Sora 再不開放使用,真的要被偷家了!今日,舊金山新創公司 Luma AI(打出一手王牌,推出新一代 AI 影片產生模型 Dream Machine。人人免費可用。

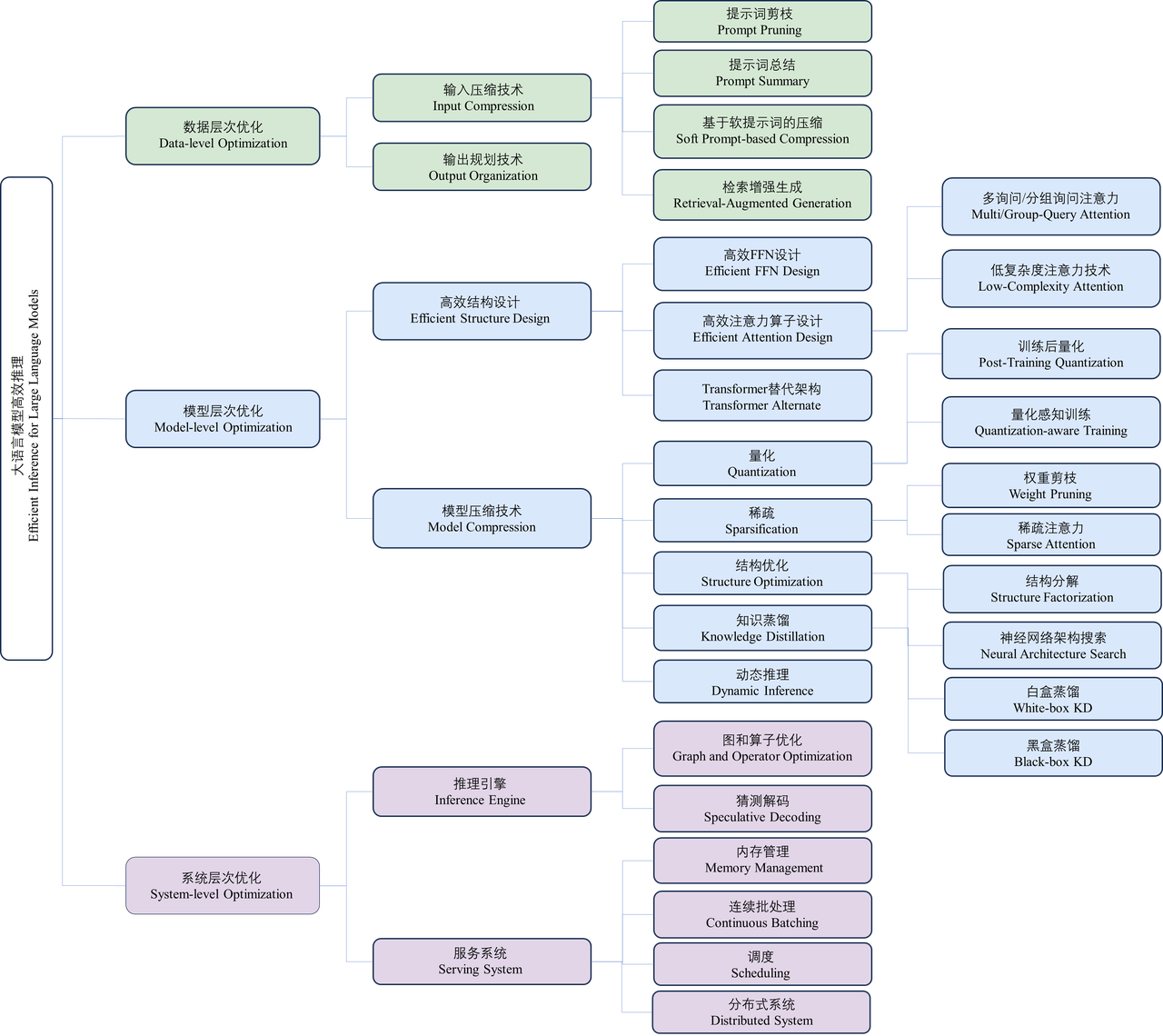
萬字綜述大模型高效推理:無問芯穹與清華、上交最新聯合研究全面解析大模型推理優化
https://news.miracleplus.com/share_link/29921
近年來,大語言模型(Large Language Models, LLMs)受到學術界和工業界的廣泛關注,得益於其在各種語言生成任務上的出色表現,大語言模型推動了各種人工智慧應用(例如ChatGPT、Copilot等)的發展。然而,大語言模型的落地應用受到其較大的推理開銷的限制,對部署資源、使用者體驗、經濟成本都帶來了巨大挑戰。例如,將包含700億參數量的LLaMA-2-70B模型進行部署推理,至少需要6張RTX 3090Ti顯示卡或2張NVIDIA A100顯示卡,以部署在A100顯示卡上為例,該模型產生512長度的詞塊(token)序列需要耗時超過50秒。許多研究工作致力於設計最佳化大語言模型推理開銷的技術,優化模型的推理延遲、吞吐、功耗和儲存等指標,成為許多研究的重要目標。為了對這些最佳化技術有更全面、更有系統的認知,為大語言模型的部署實踐和未來研究提供建議和指南,來自清華大學電子工程系、無問芯穹和上海交通大學的研究團隊對大語言模型的高效推理技術進行了一次全面的研究和整理,在《A Survey on Efficient Inference for Large Language Models》(簡稱LLM Eff-Inference)這篇萬字長文綜述將領域相關工作劃分歸類為三個最佳化層次(即資料層、模型層和系統層),並逐層介紹和總結相關技術工作。此外,該工作也對造成大語言模型推理不高效的根本原因進行分析,並基於對目前已有工作的綜述,深入探討高效推理領域未來應關注的場景、挑戰和路線,為研究者提供可行的未來研究方向。
「AI+物理先驗知識」,浙大、中國科學院通用蛋白質-配體交互作用評分方法登Nature子刊
https://news.miracleplus.com/share_link/29922
蛋白質就像是身體中的精密鎖具,而藥物分子則是鑰匙,只有完美契合的鑰匙才能解鎖治療之門。科學家一直在尋找高效的方法來預測這些「鑰匙」和「鎖」之間的匹配度,即蛋白質-配體相互作用。然而,傳統的數據驅動方法往往容易陷入「死記硬背」,記住配體和蛋白質訓練數據,而不是真正學習它們之間的相互作用。近日,浙江大學和中國科學院研究團隊,提出了一種名為 EquiScore 的新型評分方法,利用異構圖神經網路整合物理先驗知識,並在等變幾何空間中表徵蛋白質-配體相互作用。 EquiScore 是基於一個新資料集進行訓練,該資料集採用多種資料增強策略和嚴格的冗餘消除方案建構。在兩個大型外部測試集上,與其他 21 種方法相比,EquiScore 始終名列前茅。當 EquiScore 與不同的對接方法一起使用時,它可以有效增強這些對接方法的篩選能力。 EquiScore 在一系列結構類似物的活性排序任務中也表現出色,顯示其具有指導先導化合物優化的潛力。最後,研究了 EquiScore 的不同可解釋性水平,這可能為基於結構的藥物設計提供更多見解。
