8月27日大模型日報合輯

【8月27日大模型日報合輯】資訊:OpenAI、Adobe 和微軟支持加州強制AI內容浮水印法案;KDD 2024中國隊閃耀登場
OpenAI、Adobe 和微軟支持加州強制AI內容浮水印法案
連結:https://news.miracleplus.com/share_link/38717
OpenAI、Adobe和微軟三大科技公司表示支持加州即將通過的AB 3211法案,該法案要求科技公司對AI產生的內容進行識別。這項法案要求AI產生的照片、影片和音訊的元數據中加入水印,並且要求大型線上平台(如Instagram或X)以普通觀眾能夠理解的方式標識AI生成內容。
背景資訊: AB 3211法案的初始版本曾被代表Adobe、微軟等大型軟體製造商的貿易組織反對,認為該法案「不可行」且「負擔過重」。然而,在法案修改後,這些公司態度發生了轉變,並表示支持。這些科技公司都是內容來源和真實性聯盟(C2PA)的成員,C2PA幫助創建了廣泛使用的AI內容識別標準
KDD 2024中國隊閃耀登場
連結:https://news.miracleplus.com/share_link/38718
KDD 2024大會在西班牙巴塞隆納隆重舉行,吸引了全球頂尖學者和企業代表齊聚,展示了資料科學領域的最新技術成果。中國團隊表現出色,清華大學、阿里巴巴、松鼠Ai等大學和企業的研究成果被收錄,展現了中國在資料探勘領域的領先地位。
大會涵蓋了資料探勘、知識發現、預測分析等多個領域,並深入探討了新興技術在教育和金融產業的應用趨勢。松鼠Ai代表中國科技企業在生成式人工智慧和教育科技創新領域進行了深度分享。
會議亮點包括主題演講和圓桌討論,專家們探討了大語言模型(LLM)的認知能力、AI與自然環境的共生,以及AI在教育領域的應用等前沿話題。特別是中國團隊在人工智慧教育領域的實踐和探索,並得到了廣泛關注和認可。

位元組成立大模型研究院
連結:https://news.miracleplus.com/share_link/38719
字節跳動正在秘密籌備成立大模型研究院,並大力招攬頂尖AI人才,顯示大模型已成為公司的策略重點。知情人士透露,已有外部AI專家加入研究院。此外,原序智科技創辦人秦禹嘉和原零一萬物核心成員黃文灝也已加入位元組的大模型團隊,儘管尚未明確是否隸屬於新成立的研究院。
字節跳動自去年起逐步公開大模型相關進展,推出了自主研發的底層大模型“雲雀”和AI對話產品“豆包”,並成立了專注AI應用的內部項目Flow。隨著AI產品在國內外的不斷擴展,位元組跳動開始從外部引進更多人才,改變了以往主要依賴內部業務線的做法。黃文灝作為AI領域的資深專家,曾在微軟亞洲研究院和智源研究院有豐富的研究和應用經驗,此次加入字節進一步加強了其大模型團隊的實力。

谷歌系AI新創公司困境
連結: https://news.miracleplus.com/share_link/38720
這篇文章探討了由前Google員工創立的AI新創公司在面對大科技公司競爭時所遇到的困境。許多Google系AI新創公司在成立短短幾年內紛紛被收購或面臨重重挑戰,原因包括學術背景的創始人缺乏商業運作經驗、AI開發的高昂成本以及投資者的態度轉變。文章也列舉了幾家被認為可能成為收購目標的AI公司,分析了他們的現狀和麵臨的挑戰

大模型晶片轟向Hot Chips頂會
連結:https://news.miracleplus.com/share_link/38721
在2024年Hot Chips大會上,AI晶片成為焦點。 IBM、FuriosaAI等公司展示了創新的AI晶片,特別是FuriosaAI的第二代資料中心AI晶片RNGD,專為大模型推理而設計。 RNGD採用台積電5nm工藝,具有高能效、可編程性和256MB片上SRAM,性能超越了當前領先的GPU,特別是在運行大型語言模型如Llama 3.1時表現出色。 IBM發布了新一代Telum II處理器,內建AI加速器Spyre,也展示了在大型主機處理器上運行AI模型的能力。 FuriosaAI強調其晶片在能源效率和成本方面的優勢,並稱其解決了資料中心大規模AI推理的實際問題。 TCP架構和張量收縮處理器(TCP)技術是RNGD的核心,提供了高效的資料重複使用和運算能力,使其成為替代傳統GPU的有力競爭者。
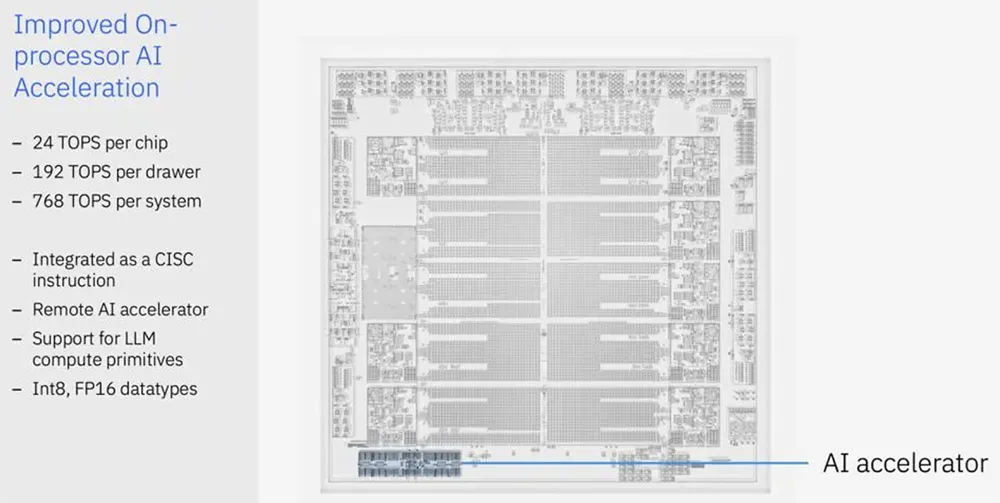
HotChip2024-Day1:AI加速器晶片
連結:https://news.miracleplus.com/share_link/38722
在HotChip 2024的第一天,各大非雲端廠商展示了他們的AI加速器晶片。 Nvidia的Blackwell以吹噓為主,未透露微架構細節。 AMD MI300X和Intel Gaudi 3進行了展示,Tenstorrent、FuriosaAI、BRCM等也帶來了有趣的內容。
主要亮點:
1. AMD MI300X:採用Infinity Fabric Advanced Package,實現高頻寬互聯。支援FP8運算,提供256MB的Infinity Cache,主要面向推理和FineTune應用,對標Nvidia H100。
2. Intel Gaudi 3:延續脈動陣列架構,矩陣乘法引擎為256×256,增加了AGU以提升非同步運算能力。引進RoCE互聯,支援21個Fullmesh ScaleUP和3個ScaleOut。
3. SambaNova SN40L:透過擴充DDR來增加記憶體容量,支援多模態推理。新世代架構合併了PCU和PMU,提升Tensor處理能力,採用Mesh/Ring混合互聯結構。
4. Furiosa:推出新概念Tensor Contraction Processor,基於愛因斯坦求和符號進行計算,PCIe卡支援48GB HBM,採用2D Mesh片上網路。
5. Tenstorrent:採用三塊微架構設計,支援非同步存取記憶體和多種資料存取原語,支援標準乙太網路互聯並擴展至任意拓撲結構。
6. Nvidia Blackwell:雖未詳細介紹微架構,但提到計算規模翻倍,並繼續推廣FP4格式。透過NV-HBI實現10TB/s的互聯,展示了複雜的液冷系統。
7. IBM Telum 2:新一代大型主機處理器,整合了DPU和AI加速器,提供更強的運算和資料傳輸能力。
整體來看,AI加速器晶片的多樣化發展趨勢明顯,各廠商在推理、FineTune、記憶體擴展和互聯技術方面各有突破。

對話 Nexa AI:兩位史丹佛95後,做出比GPT-4o快4倍的小模型
連結:https://news.miracleplus.com/share_link/38723
Nexa AI是一家由兩位史丹佛校友創立的新創公司,專注於開發高效小模型,目標是建立「端側版Hugging Face」。公司開發的Octopus v2小模型以5億參數實現了比GPT-4o快4倍的推理速度,同時具備與GPT-4相當的性能,函數調用準確率達98%以上。公司迅速引起AI界關注,已簽約多家知名企業客戶,並獲得超千萬美元種子輪融資。
Nexa AI的新產品Octopus v3具備多模態能力,可在各種邊緣裝置上有效運行,支援文字和影像輸入。該公司最近推出了端側AI綜合開發平台“Model Hub”,整合了自研和其他先進模型,旨在為開發者提供本地部署的靈活解決方案,打造一個完整的端側AI生態系統。
創辦人認為,小模型在速度、成本、隱私保護上具備優勢,能解決大部分實際問題。透過創新的Functional Token技術,Nexa AI解決了小模型函數呼叫的問題,使其效能超越了GPT-4o。在面對大廠的競爭時,Nexa AI透過技術優勢和平台化策略尋求差異化,試圖成為端側AI領域的領導者。
