大規模モデル開発の血 – 10,000 ワードの長い記事を含む詳細なデータ エンジニアリング
大規模モデル開発の血 – 10,000 ワードの長い記事を含む詳細なデータ エンジニアリング
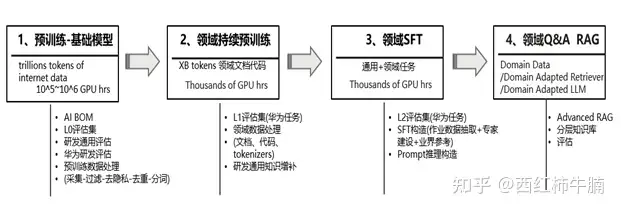
内容紹介
この記事では、研究開発における大規模言語モデル (LLM) のデータ エンジニアリングについて詳しく説明します。 効果的なデータ管理の重要性が強調されるとともに、専門分野における LLM のパフォーマンスを向上させるために、ドメイン適応型事前トレーニング、教師付き微調整、検索強化生成などの高度な技術を使用することも強調されています。 重要なポイントは、AI トレーニング データとモデル アーキテクチャに関連するメタデータを通じて透明性とリスク評価を提供する AI BOM の概念です。 この記事は、研究開発における LLM の信頼性とパフォーマンスを向上させるための包括的なアプローチで際立っており、人工知能と機械学習の分野で働く専門家にとって貴重な読み物です。
自動要約
– データの品質は、モデルのパフォーマンスとトレーニングの効率にとって非常に重要です。
– モデルのパフォーマンスを向上させ、トレーニングの効率を向上させるには、トレーニング前および微調整の段階でデータ管理が必要です。
– 事前トレーニング段階では、基本的な言語の理解と生成能力を獲得するために、一般テキストと特殊テキストを使用したトレーニングが必要です。
– 事前トレーニング データでは、品質フィルタリング、重複排除、プライバシーの削除、単語の分割などの前処理ステップが必要です。
– ドメイン事前トレーニングは、増分事前トレーニングまたはドメイン適応型事前トレーニングを通じてモデルのパフォーマンスを向上させることができます。
– 微調整フェーズでは、特定のタスクに合わせて命令形式を設計する必要があります。
– RAG テクノロジーは、モデルによって生成される応答の品質を向上させることができます。
– 推論フェーズでは、特定のタスクに適したキュー戦略を設計するためのキュー エンジニアリングが必要です。
– AIBOM の概念により、AI トレーニング データの透明性とリスク評価が向上します。
– SFT、RAG、および微調整を同時に使用して、モデルのパフォーマンスと信頼性を向上させることができます。