6月4日ビッグモデルデイリーコレクション

【6月4日ビッグモデルデイリーコレクション】ニュース:トランスフォーマーと再び戦おう!オリジナルの作者が主導する Mamba 2 が登場し、新しいアーキテクチャのトレーニング効率が大幅に向上しました。マルチモーダル モデルはポーカーのプレイを学習します。パフォーマンスは GPT-4v を上回り、新しい強化学習フレームワークは鍵
トランスフォーマーと再び戦おう!オリジナルの作者が主導する Mamba 2 が登場し、新しいアーキテクチャのトレーニング効率が大幅に向上しました。
リンク: https://news.miracleplus.com/share_link/28947
2017 年に提案されて以来、Transformer は大規模 AI モデルの主流のアーキテクチャとなり、言語モデリングでは一貫して C にランクされています。ただし、モデルのサイズが拡大し、処理する必要があるシーケンスが増大し続けるにつれて、Transformer の限界が徐々に明らかになります。明らかな欠陥は、Transformer モデルのセルフ アテンション メカニズムの計算量が、コンテキストの長さが増加するにつれて二次関数的に増加することです。数か月前、Mamba はコンテキストの長さが増加するにつれて線形スケーリングを実現できる Mamba の登場によってこの状況を打破しました。 Mamba のリリースにより、これらの状態空間モデル (SSM) は、小規模から中規模のトランスフォーマーに匹敵するか、さらにはそれを上回るように実装されました。 Mamba の著者は 2 人だけです。1 人はカーネギーメロン大学機械学習学部助教授の Albert Gu 氏、もう 1 人は Together.AI の主任科学者でプリンストン大学コンピューターサイエンス助教授の Tri Dao 氏です。 Mamba のリリース以来、コミュニティからの反応は圧倒的でした。残念なことに、マンバの論文は ICLR によって拒否され、多くの研究者を驚かせました。わずか 6 か月後、原作者の主導により、より強力な Mamba 2 が正式にリリースされました。

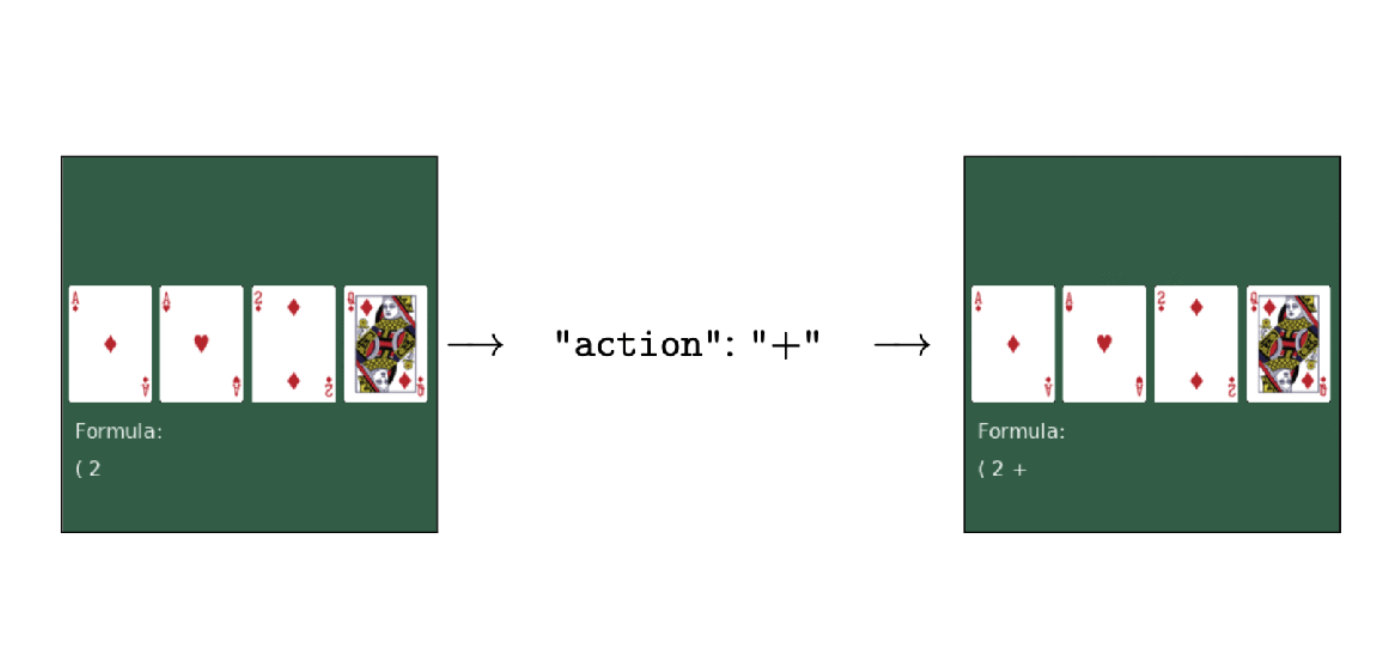
マルチモーダル モデルがポーカーのプレイを学習: パフォーマンスは GPT-4v を超え、新しい強化学習フレームワークが鍵
リンク: https://news.miracleplus.com/share_link/28948
人間のフィードバックなしで強化学習のみを使用して微調整することで、大規模なマルチモーダル モデルが意思決定を学習できるようになります。この方法で得られたモデルは、写真を見る、ポーカーをする、「12 ポイント」を数えるなどのタスクを学習し、そのパフォーマンスは GPT-4v をも上回ります。これはカリフォルニア大学バークレー校などの大学が提案している最新の微調整手法であり、研究ラインナップも非常に豪華です。
*ルカン氏、チューリング賞の3大巨頭の1人、Metaの主任AI科学者、ニューヨーク大学教授
*Sergry Levine 氏、カリフォルニア大学バークレー校の専門家、ALOHA チームのメンバー
* Xie Saining、ResNeXt() の作者、Sora 基本技術 DiT の作者
* Ma Yi、香港大学データサイエンス学部長、カリフォルニア大学バークレー校教授
Oculusの創設者パーマー・ラッキー氏は、新しいヘッドマウントディスプレイデバイスを開発中であると発表した
リンク: https://news.miracleplus.com/share_link/28949
AWE USA 2024カンファレンスは6月18日から6月20日までカリフォルニア州ロサンゼルスで開催されますが、Oculus創設者のパーマー・ラッキー氏は先日、このイベントで研究中のVRヘッドセットデバイスを正式発表する予定であると発表しました。

Karpathy と同様に、このレポートでは、LLaMa 3 を使用して高品質のネットワーク データ セットを作成する方法を説明します。
リンク: https://news.miracleplus.com/share_link/28950
Llama3、GPT-4、Mixtral などの高性能大規模言語モデルの場合、高品質の Web スケール データセットを構築することが非常に重要であることはよく知られています。ただし、最先端のオープンソース LLM の事前トレーニング データセットですら公開されておらず、その作成についてはほとんど知られていません。最近、AI の第一人者である Andrej Karpathy 氏が FineWeb-Edu という仕事を勧めました。

単一の 4090 推論可能、2000 億のスパース大規模モデル「Tiangong MoE」がオープンソース
リンク: https://news.miracleplus.com/share_link/28951
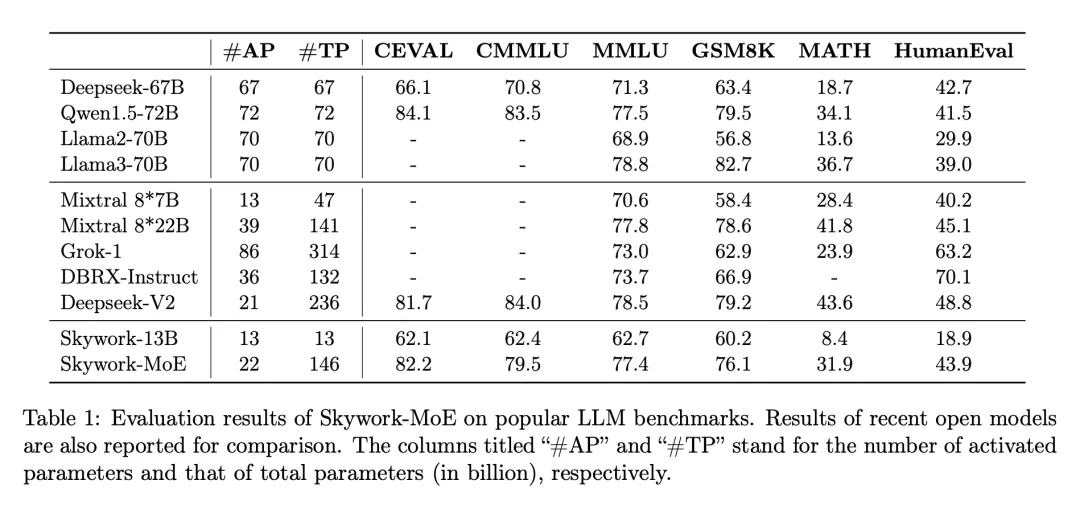
大規模モデルの波の中で、最先端の高密度 LLM のトレーニングとデプロイは、特に数百億または数千億のパラメーターのスケールにおいて、計算要件と関連コストの点で重大な課題を引き起こします。これらの課題に対処するために、専門家混合 (MoE) モデルなどのスパース モデルの重要性がますます高まっています。これらのモデルは、さまざまな特殊なサブモデル、つまり「エキスパート」に計算を分散することで、より経済的に実行可能な代替手段を提供し、リソース要件が非常に低い集中的なモデルのパフォーマンスと同等またはそれを超える可能性があります。 6 月 3 日、オープンソースの大規模モデルの分野からもう 1 つの重要なニュースが届きました。Kunlun Wanwei は、強力なパフォーマンスを維持しながら推論コストを大幅に削減する 2,000 億のスパース大規模モデル Skywork-MoE のオープンソースを発表しました。 Skywork-MoE は、Kunlun Wanwei の以前のオープンソース Skywork-13B モデル中間チェックポイント拡張に基づいており、MoE Upcycling テクノロジーを完全に適用および実装した最初のオープンソース 1000 億 MoE 大型モデルでもあります。単一の 4090 サーバーのオープンソース 1,000 億 MoE の大規模モデル。大規模なモデル コミュニティにとってさらに注目を集めているのは、Skywork-MoE のモデル重みと技術レポートが完全にオープンソースであり、アプリケーションなしで商用利用が無料であることです。
AI学習データの著作権保護:コモンズの悲劇か協力の繁栄か?
リンク: https://news.miracleplus.com/share_link/28952
GPT-4oの内蔵音声が「The Widow Sister」を模倣した事件は多くの物議を醸したが、OpenAIがWidow Sisterの声と疑われる「SKY」の音声の使用を差し止める声明を発表することで終結した。と、サウンドを侵害したことはないと否定した。しかし、「AIであっても人間の著作権は守らなければならない」というテーマが一時期話題になり、AIは制御可能かどうかという現代の神話に対する人々の既存の不安を刺激しました。最近、プリンストン大学、コロンビア大学、ハーバード大学、ペンシルベニア大学が共同で、「生成 AI の著作権の課題に対する経済的解決策」と題した、生成 AI の著作権保護のための新しい計画を立ち上げました。

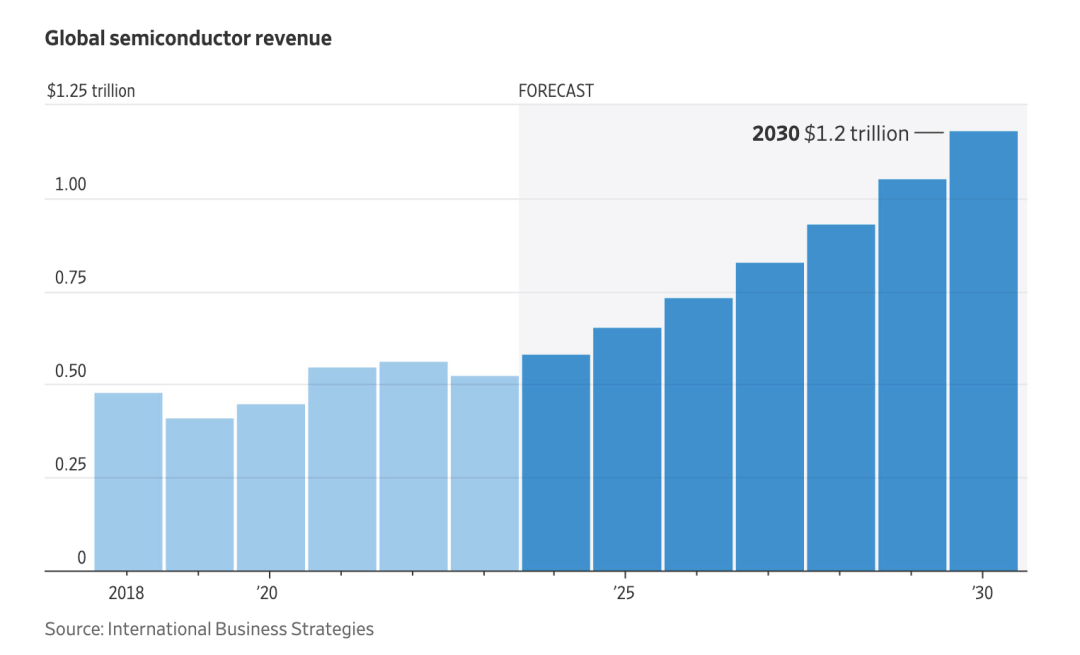
ウォール街は世界的なチップ戦争を評価しています!市場規模は1兆米ドルに達する見込み
リンク: https://news.miracleplus.com/share_link/28953
ウォール・ストリート・ジャーナルによると、世界的なチップ争奪戦が激化するにつれ、チップ産業の規模は今世紀末までに倍増して1兆ドルに達すると予想されている。各国政府は、自動車からエレクトロニクス、人工知能に至るまでの産業を支えるチップの国内生産を増やす取り組みを強化している。世界中の企業がこの時流に乗ろうと競い合っています。チップ業界のコンサルティング会社であるインターナショナル・ビジネス・ストラテジーズによると、世界の半導体収益は今世紀末までに1兆米ドルを超えると予想されています。 国内生産能力の向上により、一部の地域では特定のプロセス分野に強みを持ち、他の地域では弱点を持つ高度に専門化された半導体サプライチェーンが多様化する可能性がある。たとえば、米国企業はチップ設計の多くの分野で主導権を握っていますが、台湾、韓国、中国の企業はその後の生産および組み立て段階を支配しています。