2月18日~19日のビッグモデル日報集

【2月18日~19日のビッグモデル日報集】ポスト空時代、CV担当者はどうモデルを選ぶのか? 畳み込みまたは ViT、教師あり学習または CLIP パラダイム; Sora の技術的ルートを明らかに: コア メンバーはバークレー出身で、基礎論文は CVPR によって拒否されました; OpenAI を辞めて失業した Karpathy は新しい大規模モデル プロジェクトを開始し、星の数が1日1000個を突破、NVIDIA初公開の最速AIスーパーコンピュータ:H100 GPUを4608基搭載
ポストSoraの時代、CV担当者はどのようにモデルを選ぶのでしょうか? 畳み込みまたは ViT、教師あり学習または CLIP パラダイム
リンク: https://news.miracleplus.com/share_link/18656
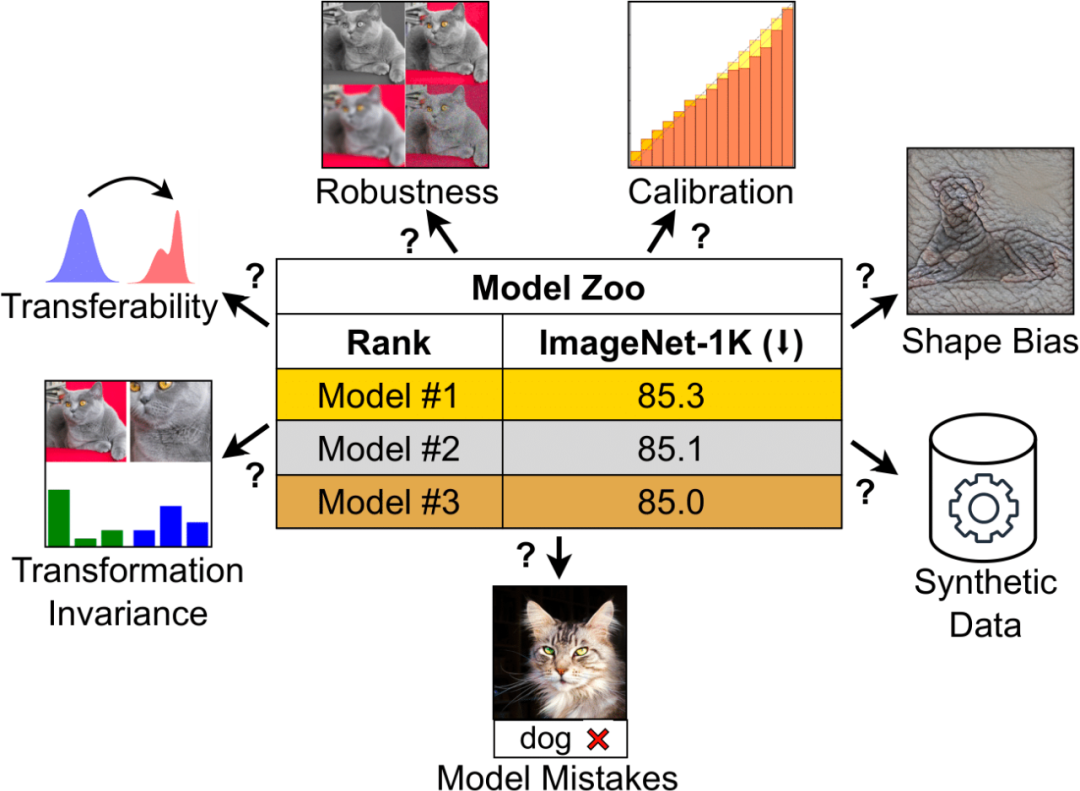
ImageNet の精度は長い間、モデルのパフォーマンスを評価するための主要な指標であり、ディープ ラーニング革命の最初の火付け役となったのです。 しかし、今日のコンピューティング ビジョンの分野では、この指標はますます「十分」ではなくなりつつあります。 コンピューター ビジョン モデルはますます複雑になっているため、初期の ConvNet から Vision Transformers に至るまで、利用可能なモデルの種類が大幅に増加しました。 同様に、トレーニング パラダイムは、ImageNet での教師ありトレーニングから、自己教師あり学習および CLIP のような画像とテキストのペアのトレーニングに進化しました。 ImageNet は、さまざまなアーキテクチャ、トレーニング パラダイム、データによって生成される微妙なニュアンスを捉えることができません。 ImageNet の精度のみで判断すると、異なるプロパティを持つモデルが似ているように見える可能性があります。 この制限は、モデルが ImageNet の特異性をオーバーフィットし始めて精度が飽和し始めると、より顕著になります。 CLIP は注目に値する例です。CLIP の ImageNet の精度は ResNet と似ていますが、そのビジュアル エンコーダははるかに堅牢で転送可能です。 これらの質問は、この分野の実務者に新たな混乱をもたらしました: 視覚モデルを測定するにはどうすればよいですか? そして、ニーズに合ったビジュアルモデルを選択するにはどうすればよいでしょうか? 最近の論文では、MBZUAI と Meta の研究者がこの問題について詳細な議論を行っています。
視覚言語モデルに空間推論を行わせると、Google は再び新しくなります
リンク: https://news.miracleplus.com/share_link/18657
視覚言語モデル (VLM) は、画像説明、視覚的質問応答 (VQA)、具体化された計画、行動認識などを含む幅広いタスクで大幅な進歩を遂げています。 ただし、ほとんどの視覚言語モデルには、3 次元空間内のオブジェクトの位置や空間関係を理解する必要があるタスクなど、空間推論において依然としていくつかの困難があります。 この問題に関して、研究者はしばしば「人間」からインスピレーションを得ます: 身体化された経験と進化的発達を通じて、人間は固有の空間的推論スキルを備えており、物体の相対的な位置や距離と合計の推定などの空間的関係を容易に決定できます。複雑な思考連鎖や暗算に適しています。 直接的な空間推論タスクにおけるこの熟練度は、現在の視覚言語モデルの能力の限界とは対照的であり、視覚言語モデルに人間のような空間推論能力を与えることができるのか?という切実な研究疑問を提起します。 最近、Google は空間推論機能を備えた視覚言語モデル、SpatialVLM を提案しました。

100 万トークンがあれば、一度に 1 時間の YouTube 動画を分析でき、「ビッグワールド モデル」が普及しつつあります。
リンク: https://news.miracleplus.com/share_link/18658
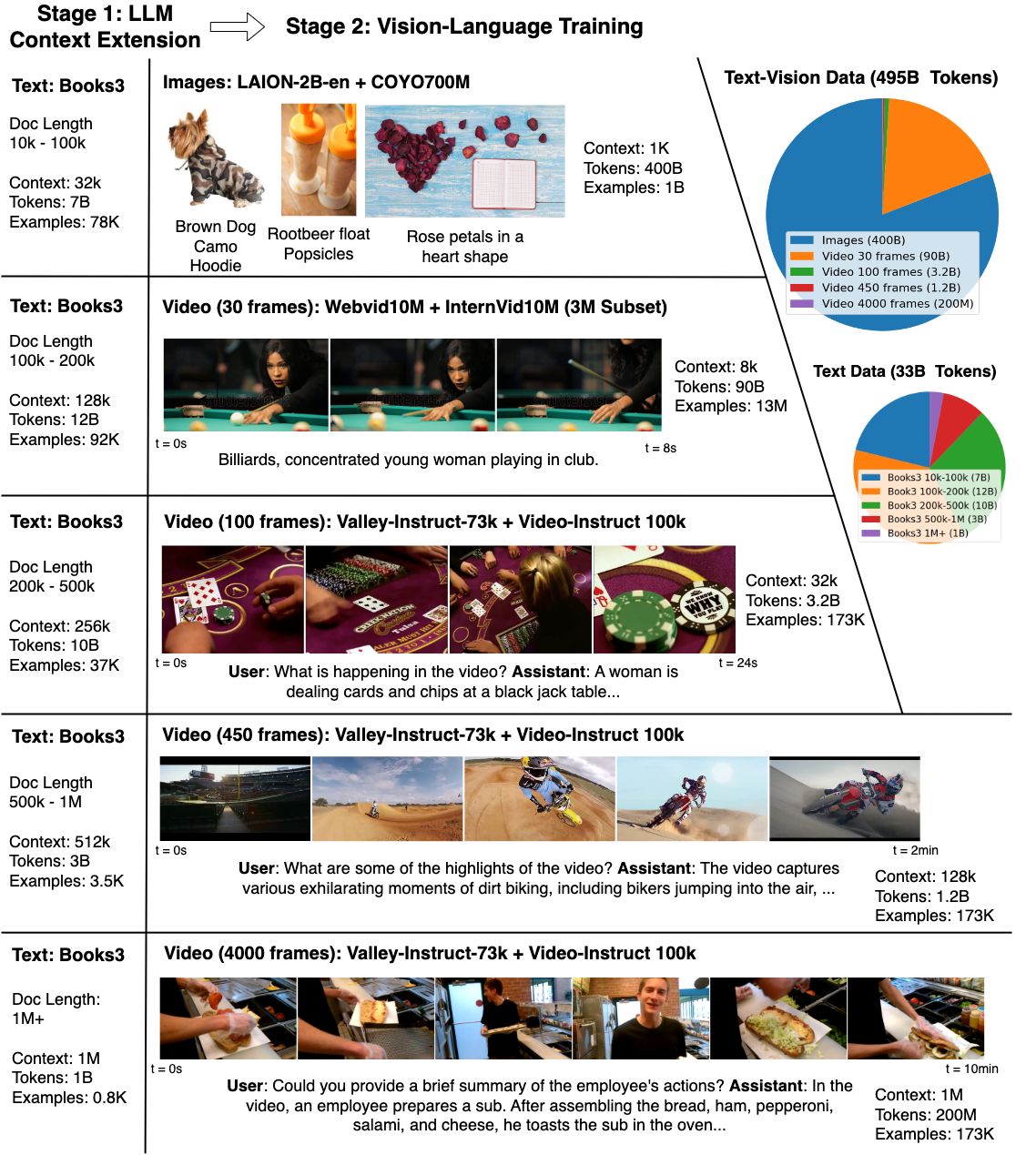
Sora に限らず、現在、大規模なモデルは急速に発展していますが、現実世界の内容を言語で説明するのが難しく、モデルを理解するのが非常に難しいなどの欠点もあります。複雑な長距離タスクを処理するのは困難です。 ビデオ モデルの出現により、この問題はある程度軽減され、言語や静止画像に欠落している時間情報が提供されるため、LLM にとって非常に価値があります。 テクノロジーが進歩するにつれて、モデルはテキストの知識と物理的世界をより深く理解し始め、それによって人間を助けます。 ただし、何百万ものビデオや言語シーケンスのトークンから学習することは、メモリの制約、計算の複雑さ、データセットの制限により困難です。 これらの課題に対処するために、カリフォルニア大学バークレー校の研究者らは、さまざまなビデオや書籍を含む大規模なデータセットを編集し、RingAttendant テクノロジーを使用して長いシーケンスでスケーラブルなトレーニングを実行するラージ ワールド モデル (LWM) を提案しました。 4K ~ 1M トークン。
Windows と Office を直接起動し、大規模モデル エージェントでコンピュータを操作します
リンク: https://news.miracleplus.com/share_link/18659
AI アシスタントの未来について話すとき、「アイアンマン」シリーズのまばゆいばかりの AI アシスタント、ジャービスを思い出さないわけにはいきません。 ジャービスはトニー・スタークの右腕であるだけでなく、先端技術の伝達者でもあります。 今日、大型モデルの出現により人間の道具の使い方が覆され、私たちはそのような SF のシナリオに一歩近づいているのかもしれません。 マルチモーダル エージェントが人間と同じようにキーボードとマウスを介して周囲のコンピュータを直接制御できるとしたら、それはなんと素晴らしい画期的な進歩となるでしょう。 最近、吉林大学人工知能学部は、大規模な視覚言語モデルを使用してコンピューター GUI を直接制御し、この想像力を現実にマッピングする最新の研究「ScreenAgent: 視覚言語モデル駆動型コンピューター制御エージェント」を発表しました。 この研究では、ScreenAgent モデルを提案しました。これは、補助的な位置決めタグを必要とせずにコンピューターのマウスとキーボードを直接制御する VLM エージェントの使用を初めて検討し、大規模なモデルでコンピューターを直接操作するという目標を達成しました。 さらに、ScreenAgent は、「計画-実行-反映」の自動化プロセスを通じて、GUI インターフェイスの継続的な制御を初めて実現します。 この研究は、人間とコンピューターの対話方法の探求と革新であり、同時に正確な位置情報を備えたオープンソースのデータセット、コントローラー、トレーニングコードなどを提供します。
Sora の技術ロードマップを明らかに: コアメンバーはバークレー出身、基本論文は CVPR によって拒否された
リンク: https://news.miracleplus.com/share_link/18660
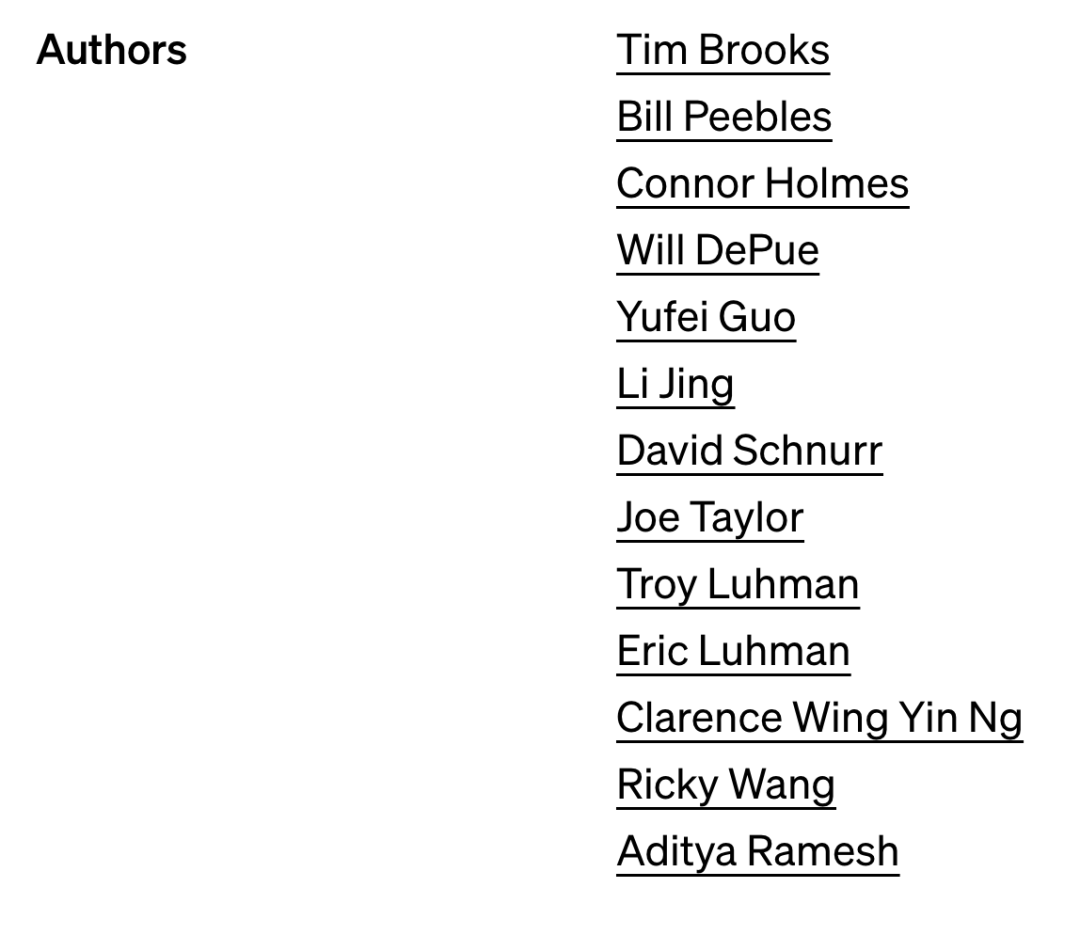
ここ数日、世界中のベンチャーキャピタルの会合でSoraの話題が持ち上がっているという。 昨年初めに ChatGPT がテクノロジー全体の軍拡競争を引き起こして以来、AI によって生成された新しいビデオ トラックに取り残されることを誰も望んでいません。 この問題については、人々は長い間予測していましたが、予想外でもありました: AI 生成ビデオは、テキスト生成と画像生成に続く継続的な技術開発の方向性です。以前は、多くのテクノロジー企業が独自のビデオ生成技術の立ち上げを急いでいたのです。 しかし、OpenAI が Sora をリリースしたとき、私たちはすぐに「新しい世界を発見した」という感覚を抱きました。その効果は、これまでのテクノロジーよりも数段上でした。 今回のSoraの参加者のうち、コアメンバーとして知られているのは、R&DリーダーのTim Brooks氏、William Peebles氏、システムリーダーのConnor Holmes氏など。 このメンバーの情報にも注目が集まっている。
OpenAIを辞めて失業したKarpathyさんが新たに大規模なモデルプロジェクトを立ち上げたところ、星の数は1日で1,000を超えた。
リンク: https://news.miracleplus.com/share_link/18661
ここ数日、OpenAI は非常に活発で、まず AI の第一人者である Andrej Karpathy 氏が辞任を正式に発表し、次にビデオ生成モデルの Sora 氏が AI 界に衝撃を与えました。
OpenAI からの離脱を発表した後、Karpathy 氏はツイートした、「今週は休めます。しかし、鋭い目を持つネチズンは、LLM ワード セグメンテーションで一般的に使用される BPE (バイト ペア エンコーディング、ワード) に特化した Karpathy の新しいプロジェクト minbpe を発見しました」 .coding) アルゴリズムにより、最小限でクリーンな教育的なコードが作成されます。わずか 1 日で、プロジェクトの GitHub スターが 1.2k に達しました。

ソラは物理世界を理解していますか? AI界の重鎮の間でブレインストーミングが行われている
リンク: https://news.miracleplus.com/share_link/18662
Sora は物理エンジンですか、それとも世界モデルですか? チューリング賞受賞者のヤン・ルカン氏、ケラス・フランソワ・ショレ氏の父親らが、徹底的に議論している。 数秒のビデオしか生成できなかった以前のモデルとは異なり、Sora は生成されるビデオの長さを突然 60 秒に延長しました。 さらに、Prompt でユーザーが提示した要件を理解するだけでなく、物理世界における人や物体の存在方法も把握できます。

資金調達が10億米ドルを超え、AI企業「Dark Side of the Moon」がSequoia、Xiaohongshu、Meituan、Alibabaから新たな投資を受ける
リンク: https://news.miracleplus.com/share_link/18663
AIスタートアップ「ダークサイド・オブ・ザ・ムーン」はこのほど、10億ドルを超える新たな資金調達ラウンドを完了し、投資家にはセコイア・チャイナ、小紅書、美団、アリババなどが名を連ね、古くからの株主も参加した。 Dark Side of the Moon の最後の資金調達ラウンドは 2023 年に 2 億米ドルを超え、投資家には Sequoia China、Zhen Fund などが含まれていました。 今回の資金調達により、ダークサイド・オブ・ザ・ムーンの評価額は約25億米ドルに達し、国内の大型模型分野における有力企業の一つとなった。

ザッカーバーグ氏の最新の会話: スマートフォンは消えることはなく、AR は主流のモバイル コンピューティング デバイスとなり、XR はデスクトップ コンピューティング デバイスとなり、生成 AI は人間と機械のコミュニケーションを可能にするでしょう
リンク: https://news.miracleplus.com/share_link/18664
Metaの創設者兼最高経営責任者(CEO)のマーク・ザッカーバーグ氏は先週、Morning Brewの独占インタビューに参加した。 インタビュー中、マークは、AI と AR テクノロジーが将来、私たちの働き方、生活方法、社交方法を変えるだろうとの信念を表明しました。 Xiao Zha 氏は、AR スマート グラスが次世代のコンピューティング携帯電話および道路上で使用されるコンピューティング プラットフォームになると信じていますが、XR ヘッドセットは次世代のコンピュータまたはテレビ画面になる可能性があります。電話のほうがより重要なデバイスになるかもしれませんし、メガネのほうがより重要でどこにでもあるものになるかもしれませんが、どちらも理にかなっています。

ソラはマスクが正しかったことを証明したが、テスラと人類は負けたかもしれない
リンク: https://news.miracleplus.com/share_link/18665
ソラの打ち上げ、ムスクは最も複雑な感情を持っているかもしれません。 それは彼自身の初期の OpenAI との関わりだけでなく、ソラがここ数年テスラが模索してきた方向性を実際に認識しているからでもあります。 2月18日、マスク氏はテクノロジーアンカー@Dr.KnowItAllによる「OpenAIの爆弾はテスラの理論を裏付ける」というタイトルのビデオの下にメッセージを残し、「テスラは正確な物理原理を使用して現実世界を作り出すことができた。このビデオは約1年前のものである」と述べた。 」 その後、彼は X に関する 2023 年のビデオを転送しました。そこでは、テスラの自動運転担当ディレクターであるアショク・エルスワミーが、テスラが AI を使用して現実世界の運転をシミュレートする方法を紹介していました。 動画では、AIが異なる角度からの7つの走行動画を同時に生成し、同時に「直進」「車線変更」などの指示を入力するだけで、7つの動画が同時に切り替わります。

NVIDIA、現時点で最速の AI スーパーコンピューターを初めて公開: 4608 基の H100 GPU を搭載
リンク: https://news.miracleplus.com/share_link/18666
最近、NVIDIA は、最新のエンタープライズ向け AI スーパーコンピューター Eos を初めて外部に発表しました。これは、NVIDIA の最速 AI スーパーコンピューターでもあります。 レポートによると、Eos には合計 4,608 個の Nvidia H100 GPU と 1,152 個の Intel Xeon Platinum 8480C プロセッサ (各 CPU に 56 コア) が搭載されています。 Eos は、NVIDIA Mellanox Quantum-2 InfiniBand テクノロジーも使用しており、最大 400 Gb/s のデータ転送速度を実現します。これは、大規模な AI モデルのトレーニングやシステム拡張に不可欠です。
