2月2日大模型日報合集

【2月2日大模型日報合集】A16Z 最新AI 洞察|2023 年是AI 視頻元年,2024 年還有這些難題需要解決;年齡兩歲,教齡一年半:嬰兒AI訓練師登上Science;2B 參數效能超Mistral-7B:面壁智慧多模態端側模型開源
大模型也有小偷? 為保護你的參數,上交大給大模型製作「人類可讀指紋」
連結:https://news.miracleplus.com/share_link/17446
大模型的預訓練需要耗費鉅量的運算資源與數據,因而預訓練模型的參數也正成為各大機構重點保護的核心競爭力與資產。 然而,不同於傳統的軟體智慧財產權保護可以透過比對原始碼來確認是否存在程式碼盜用,而對預訓練模型參數盜用的判斷有以下兩方面的新問題:1) 預訓練模型的參數,尤其是千 億級模型的參數,通常不會開源。 2) 更重要的是,預訓練模型的輸出和參數都會隨著 SFT、RLHF、continue pretraining 等下游處理步驟而改變。 這使得無論是基於模型輸出還是基於模型參數,都很難判斷某一模型是否是基於另一現有模型微調得來。 因此,對大模型參數的保護是一個尚缺乏有效解決方案的全新問題。 為此,來自上海交通大學林洲漢老師的Lumia 研究團隊研發了一種人類可讀的大模型指紋,這一方法可以在不需要公開模型參數的條件下,有效識別各個大模型之間的血統 關係。

阿里全新Agent玩手機:刷短影片自主點讚評論,也學會了跨應用程式操作
連結:https://news.miracleplus.com/share_link/17447
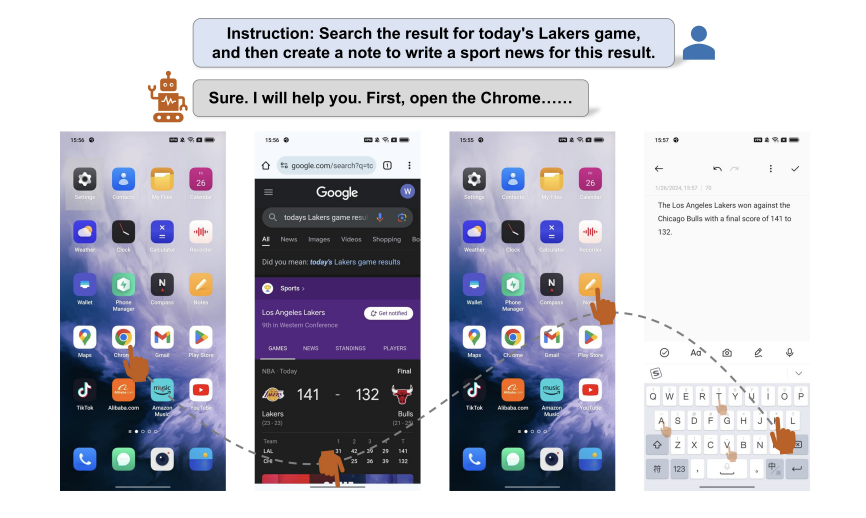
會操縱手機的智能體,又迎來了全新升級! 新的Agent打破了APP的界限,能夠跨應用程式完成任務,成為了真·超級手機助手。 例如根據指示,它可以自行搜尋籃球比賽的結果,然後根據賽況在備忘錄中撰寫文稿。 來自阿里的一篇最新論文,展示了全新手機操縱智能體框架Mobile-Agent,可以玩10款應用,還能跨越APP完成用戶交給的任務,而且即插即用無需訓練。 依托多模態大模型,整個操縱過程完全基於視覺能力實現,不再需要給APP編寫XML操作文檔。
代謝資料集上四項指標達94%~98%,西南交大團隊開發多尺度圖神經網路框架,協助藥物研發
連結:https://news.miracleplus.com/share_link/17448
在藥物研發過程中,了解分子與代謝路徑之間的關係,對於合成新分子和優化藥物代謝機制至關重要。 西南交通大學楊燕/江永全團隊開發了一種新型的多尺度圖神經網路框架MSGNN,將化合物與代謝路徑連結起來。 它包括特徵編碼器、子圖編碼器和全局特徵處理器三個部分,分別學習了原子特徵、子結構特徵和額外的全局分子特徵,這三個尺度的特徵可賦予模型更全面的資訊。 此框架在 KEGG 代謝路徑資料集上的表現優於現有方法,Accuracy、Precision、Recall、F1分別達到98.17%、94.18%、94.43%、94.30%。 並且,團隊也採用了圖增強策略將訓練集中的資料量擴充了十倍,使模型訓練更加充分。

A16Z 最新 AI 洞察|2023 年是 AI 視訊元年,2024 年還有這些難題需要解決
連結:https://news.miracleplus.com/share_link/17449
這是 A16Z 合夥人 Justine Moore 最新發布的 2024 年 AI 影片展望。 Justine 提到,2023 年對於 AI 影片領域來說,是突破性的一年。 2023 年初時,公開的文字轉視訊模型尚不存在。 僅僅 12 個月後,數十種影片生成產品已被積極使用,全球有數百萬用戶透過文字或圖像提示創建短片。 這些產品仍有相對的限制——大多數生成的影片長度為 3~4 秒,輸出的品質參差不齊,像角色一致性這樣的問題還未解決。 我們距離用單一文字提示(或甚至多個提示!)創造出皮克斯級別的短片還有很長的路要走。 然而,過去一年在視訊生成領域所見證的進步表明,我們正處於一場巨大變革的初期階段,這與 A16Z 在圖像生成領域所見到的相似。 我們正在見證文字轉視訊模型的持續改進,以及像圖像轉視訊和視訊轉視訊這樣的衍生技術正在獲得動力。 為了幫助理解這場創新的爆炸,A16Z 追蹤了到目前為止最重要的發展、值得關注的公司,以及這個領域中剩餘的基本問題。

比肩GPT-4,商湯日日新大幅升級4.0,多模態能力領先一步
連結:https://news.miracleplus.com/share_link/17450
商湯的大模型體系「日日新 SenseNova」今天剛發布了 4.0 版,不論語言能力還是文生圖能力都有全面升級,還自備低門檻的落地工具。 新一代SenseNova 不僅在大語言模型、文生圖模型等方面進行了重大升級,部分垂直領域能力超越GPT-4,還發布了全新多模態大模型,並面向數據分析、醫療等場景提供了全新版本 ,讓大模型通用能力適配到了更多領域。
年齡兩歲,教齡一年半:嬰兒AI訓練師登上Science
連結:https://news.miracleplus.com/share_link/17451
在公開訪談中,圖靈獎得主 Yann LeCun 多次提到,現在的 AI 模型和人類嬰兒相比,學習效率實在太低了。 那麼,如果讓一個 AI 模型去學習嬰兒頭戴攝影機拍到的東西,它能學到什麼? 最近,Science 雜誌上的一篇論文進行了初步嘗試。 研究發現,即使資料有限,AI 模型也能從10 到100 個例子中學到單字- 視覺所指物件之間的映射,而且能夠零樣本地泛化到新的視覺資料集,並實現多模態對齊 。 這說明,利用當今的人工智慧工具,從嬰兒的角度進行真正的語言學習是可能的。
亞馬遜推出人工智慧購物助理 TRufusJ
連結:https://news.miracleplus.com/share_link/17452
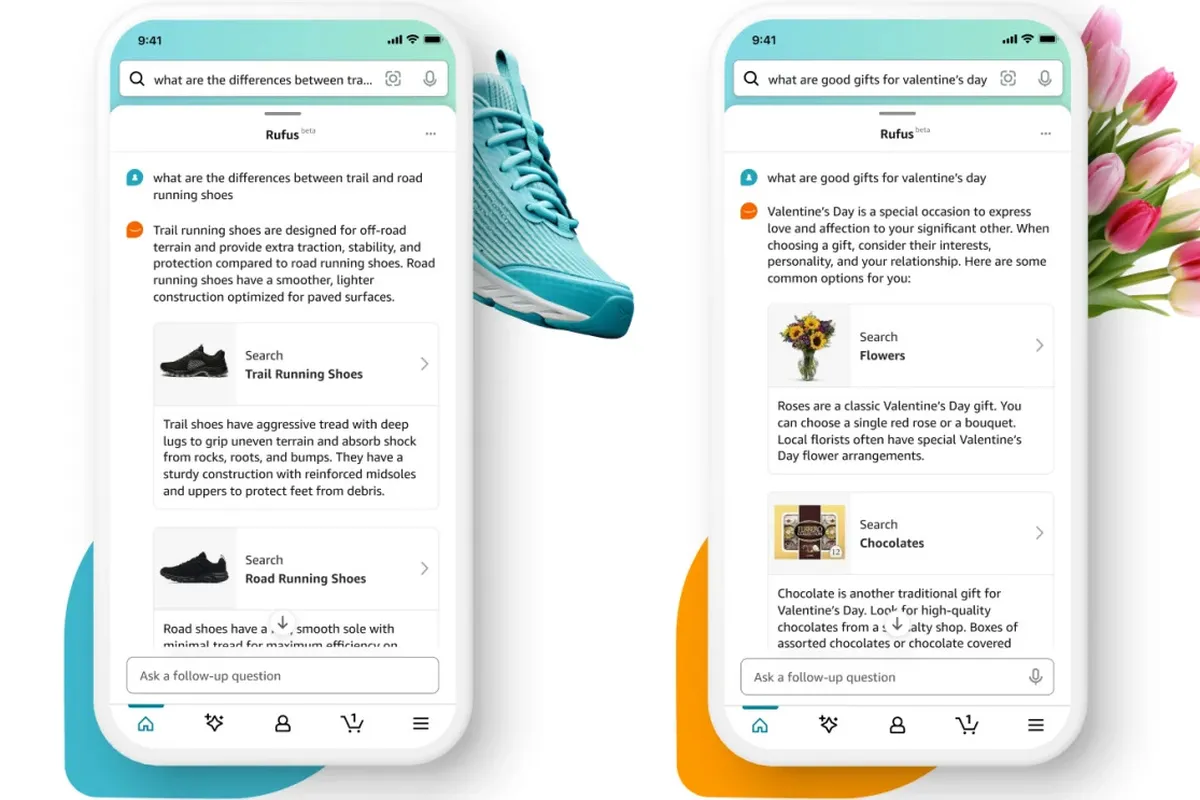
亞馬遜推出名為 Rufus 的人工智慧購物助手,與該公司的柯基吉祥物同名。 該聊天機器人接受了亞馬遜產品庫、客戶評論以及網路資訊的訓練,使其能夠回答有關產品的問題、進行比較、提供建議等。 Rufus 仍處於測試階段,只會出現在「特定客戶」中,然後在未來幾週內向更多用戶推出。
2B參數效能超Mistral-7B:面壁智慧多模態端側模型開源
連結:https://news.miracleplus.com/share_link/17453
在大模型不斷朝著大體量方向前進的同時,最近一段時間,人們在最佳化和部署方面也取得了成果。 2 月 1 日,面壁智慧聯合清華 NLP 實驗室在北京正式發布了旗艦端側大模型「面壁 MiniCPM」。 新一代大模型被稱為「性能小鋼炮」,直接擁抱終端部署,同時也具有同量級最強的多模態能力。 面壁智能本次提出的 MiniCPM 2B 參數量僅 20 億,使用 1T token 的精選資料訓練。 這是一個參數量上與 2018 年 BERT 同級的模型,面壁智能在其之上實現了極致的性能優化與成本控制,讓該模型可以「越級打怪」。 面壁智慧聯合創始人、CEO 李大海將新模型與業內知名開源大模型 Mistral-7B 進行了對比,在多項主流評測榜單上,MiniCPM 2B 的性能全面超越了後者。
