6月4日大模型日報合輯

【6月4日大模型日報合輯】資訊:再戰Transformer!原作者帶隊的Mamba 2來了,新架構訓練效率大幅提升;多模態模型學會打撲克:表現超越GPT-4v,全新強化學習架構是關鍵
再戰Transformer!原作者帶隊的Mamba 2來了,新架構訓練效率大幅提升
連結:https://news.miracleplus.com/share_link/28947
自 2017 年被提出以來,Transformer 已成為 AI 大模型的主流架構,一直穩居語言建模方面 C 位元。但隨著模型規模的擴展和需要處理的序列不斷變長,Transformer 的限制也逐漸凸顯。一個很明顯的缺陷是:Transformer 模型中自註意力機制的計算量會隨著上下文長度的增加而呈平方級增長。幾個月前,Mamba的出現打破了這個局面,它可以隨上下文長度的增加實現線性擴展。隨著 Mamba 的發布,這些狀態空間模型 (SSM) 在中小型規模上已經實現了與 Transformers 匹敵,甚至超越 Transformers。 Mamba 的作者只有兩位,一位是卡內基美隆大學機器學習系助理教授 Albert Gu,另一位是 Together.AI 首席科學家、普林斯頓大學電腦科學助理教授 Tri Dao。 Mamba 問世之後的這段時間裡,社區反應熱烈。可惜的是,Mamba 的論文卻慘遭 ICLR 拒稿,讓一眾研究者頗感意外。僅僅六個月後,原作者帶隊,更強大的 Mamba 2 正式發布了。

多模態模型學會打撲克:表現超越GPT-4v,全新強化學習框架是關鍵
連結:https://news.miracleplus.com/share_link/28948
只用強化學習來微調,無需人類回饋,就能讓多模態大模型學會做決策!這種方法得到的模型,已經學會了看圖玩撲克、算「12點」等任務,表現甚至超越了GPT-4v。這是來自UC柏克萊等大學最新提出的微調方法,研究陣容也相當豪華:
* 圖靈獎三巨頭之一、Meta首席AI科學家、紐約大學教授LeCun
* UC柏克萊大牛、ALOHA團隊成員Sergry Levine
* ResNeXt()一作、Sora基礎技術DiT作者謝賽寧
* 香港大學資料科學院院長、UC柏克萊教授馬毅
Oculus創辦人帕爾默·拉奇宣稱自己正在研發一款全新的頭顯設備
連結:https://news.miracleplus.com/share_link/28949
AWE USA 2024大會將於6月18日至6月20日在美國加州洛杉磯舉行,而Oculus創始人帕爾默·拉奇日前宣布,他計劃在本屆活動正式宣布自己在研究的VR頭顯設備。

Karpathy點贊,這份報告教你如何用 LLaMa 3創建高品質網路資料集
連結:https://news.miracleplus.com/share_link/28950
眾所周知,對於 Llama3、GPT-4 或 Mixtral 等高效能大語言模型來說,建立高品質的網路規模資料集是非常重要的。然而,即使是最先進的開源 LLM 的預訓練資料集也不公開,人們對其創建過程知之甚少。最近,AI 大牛 Andrej Karpathy推薦了一項名為 FineWeb-Edu 的工作。

單一4090可推理,2000億稀疏大模型「天工MoE」開源
連結:https://news.miracleplus.com/share_link/28951
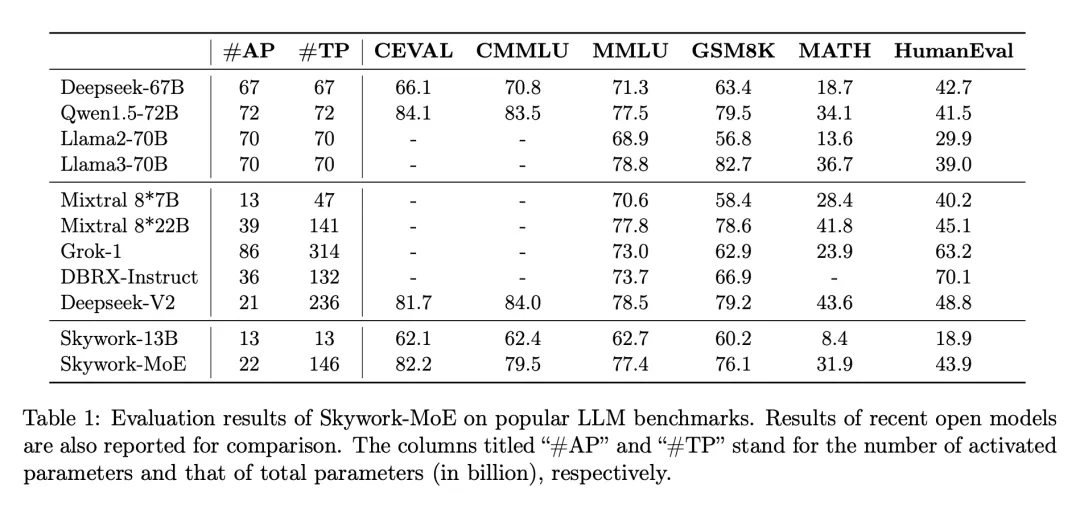
在大模型浪潮中,訓練和部署最先進的密集 LLM 在運算需求和相關成本上帶來了巨大挑戰,尤其是在數百億或數千億參數的規模上。為了應對這些挑戰,稀疏模型,如專家混合模型(MoE),已經變得越來越重要。這些模型透過將計算分配給各種專門的子模型或“專家”,提供了一種經濟上更可行的替代方案,有可能以極低的資源需求達到甚至超過密集型模型的性能。 6 月 3 日,開源大模型領域又傳來重要消息:崑崙萬維宣布開源 2 千億稀疏大模型 Skywork-MoE,在保持性能強勁的同時,大幅降低了推理成本。 Skywork-MoE 是基於先前崑崙萬維開源的Skywork-13B 模型中間checkpoint 擴展而來,是首個完整將MoE Upcycling 技術應用並落地的開源千億MoE 大模型,也是首個支持用單台4090 伺服器推理的開源千億MoE 大模型。讓大模型社群更重視的是,Skywork-MoE 的模型權重、技術報告完全開源,免費商用,無需申請。
AI訓練資料的版權保護:公地的悲劇還是合作的繁榮?
連結:https://news.miracleplus.com/share_link/28952
GPT-4o內建聲音模仿「寡姐」一案鬧的沸沸揚揚,雖然以OpenAI發布聲明暫停使用疑似寡姐聲音的「SKY」的語音、否認曾侵權聲音為階段性結束。但是,一時間「即便是AI,也得保護人類版權」這一話題甚囂塵上,更刺激起了人們本來就對AI是否可控這一現代迷思的焦慮。近日,普林斯頓大學、哥倫比亞大學、哈佛大學和賓州大學共同推出了一項關於生成式AI版權保護的新方案,題為《An Economic Solution to Copyright Challenges of Generative AI》。

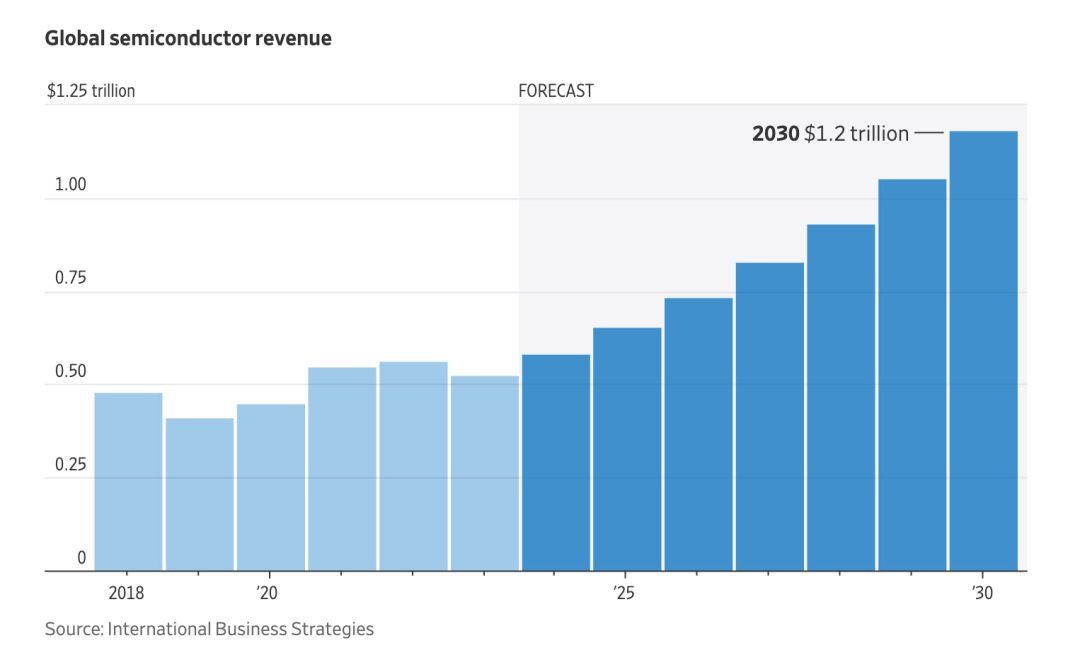
華爾街盤點全球晶片戰!市場規模將達 1 兆美元
連結:https://news.miracleplus.com/share_link/28953
根據《華爾街日報》,隨著全球晶片之爭日益升級,到本世紀末,晶片產業的規模預計將翻一番,達到 1 兆美元。各國政府加大力度,推動國內晶片生產,這些晶片為汽車、電子產品和人工智慧等各行各業提供動力。全球各地的公司都在競相加入這股熱潮。根據晶片產業顧問公司 International Business Strategies預測,到本世紀末,全球半導體收入預計將超過 1 兆美元。 國內生產能力增強可能會使高度專業化的半導體供應鏈多樣化,在某些地區,半導體供應鏈在某些製程領域具有優勢,而在其他領域則存在弱點。例如,美國公司在晶片設計的許多領域處於領先地位,而台灣、韓國和中國大陸的公司則在後期的生產和組裝階段佔據主導地位。